Симон Робинсон - C# для профессионалов. Том II
Здесь есть возможность читать онлайн «Симон Робинсон - C# для профессионалов. Том II» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2003, ISBN: 2003, Издательство: Лори, Жанр: Программирование, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:C# для профессионалов. Том II
- Автор:
- Издательство:Лори
- Жанр:
- Год:2003
- Город:Москва
- ISBN:5-85582-187-0
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
C# для профессионалов. Том II: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «C# для профессионалов. Том II»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Для кого предназначена эта книга
Основные темы книги Платформа .NET предлагает новую среду, в которой можно разрабатывать практически любое приложение, действующее под управлением Windows, а язык C# — новый язык программирования, созданный специально для работы с .NET.
В этой книге представлены все основные концепции языка C# и платформы .NET. Полностью описывается синтаксис C#, приводятся примеры построения различных типов приложений с использованием C# — создание приложений и служб Windows, приложений и служб WWW при помощи ASP.NET, а также элементов управления Windows и WWW Рассматриваются общие библиотеки классов .NET, в частности, доступ к данным с помощью ADO.NET и доступ к службе Active Directory с применением классов DirectoryServices.
Эта книга предназначена для опытных разработчиков, возможно, имеющих опыт программирования на VB, C++ или Java, но не использовавших ранее в своей работе язык C# и платформу .NET. Программистам, применяющим современные технологии, книга даст полное представление о том, как писать программы на C# для платформы .NET.
• Все особенности языка C#
• C# и объектно-ориентированное программирование
• Приложения и службы Windows
• Создание web-страниц и web-служб с помощью ASP NET
• Сборки .NET
• Доступ к данным при помощи ADO NET
• Создание распределённых приложений с помощью NET Remoting
• Интеграция с COM, COM+ и службой Active Directory
C# для профессионалов. Том II — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «C# для профессионалов. Том II», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
//выбрать все строки из таблицы products и таблицы suppliers
//проверьте, что строка соединения соответствует конфигурации сервера
SqlConnection conn=
new SqlConnection(@"server=GLYNNJ_CS\NetSDK;uid=sa;pwd=;database=northwind");
SqlDataAdapter daProd=new SqlDataAdapter("select * from products", conn);
SqlDataAdapter daSup=new SqlDataAdapter("select * from suppliers", conn);
//Заполнить DataSet из обоих SqlAdapters
daProd.Fill(ds, "products");
daSup.Fill(ds, "suppliers");
//Добавить отношение
ds.Relations.Add(ds.Tables["suppliers"].Columns["SupplierId"],
ds.Tables["products"].Columns["SupplierId"]);
//Записать Xml в файл, чтобы можно было просмотреть его позже
ds.WriteXml("..\\..\\..\\SuppProd.xml", XmlWriteMode.WriteSchema);
//загрузить данные в таблицу
dataGrid1.DataSource=ds;
dataGrid1.DataMember="suppliers";
//создать XmlDataDocument
doc=new XmlDataDocument(ds);
//Выбрать элементы productname и загрузить их в таблицу
XmlNodeList nodeLst=doc.SelectNodes("//ProductName");
foreach(XmlNode nd in nodeLst) listBox1.Items.Add(nd.InnerXml);
}
В этом примере создаются два объекта DataTablesв DataSetиз XMLProducts: Productsи Suppliers. Отношение состоит в том, что Suppliers(Поставщики) поставляют Products(Продукты). Мы создаем новое отношение на столбце SupplierIdв обоих таблицах. Вот как выглядит DataSet:
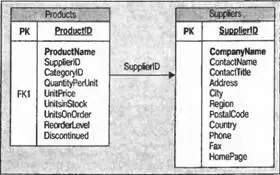
Делая такой же вызов метода WriteXml, как в предыдущем примере, мы получим следующий файл XML ( SuppProd.xml):
1
Chai
1
1
10 boxes x 20 bags
18
39
0
10
false
2
Chang
1
1
24 - 12 oz bottles
19
17
40
25
false
1
Exotiс Liquids
Charlotte Cooper
Purchasing Manager
49 Gilbert St.
London
EC1 4SD
UK
(171) 555-2222
2
New Orleans Cajun Delights
Shelley Burke
Order Adminisirator
P.O. Box 78934
New Orleans
LA
70117
USA
(100) 555-4822
#CAJUN.HTM#
Эта схема включает в себя обе таблицы данных DataTables, которые находились в DataSet. Данные также содержат все данные из обеих таблиц. Несколько продуктов и поставщиков были удалены из окончательного файла, чтобы сэкономить пространство. Как и раньше, можно сохранить только схему или только данные, передавая соответствующий параметр XmlWriteMode.
Преобразование документа XML в данные ADO.NET
Предположим что имеется документ XML, который нужно поместить в DataSetADO.NET. И вы хотите сделать это так. чтобы можно было загрузить XML в базу данных, или, может быть, связать данные с управляющим элементом данных .NET, таким как DataGrid. Таким образом, можно будет на самом деле использовать документ XML в качестве хранилища данных, и можно будет полностью исключить накладные расходы, связанные с базой данных. Вот некоторый код для начала ( ADOSample4):
private void button1_Click(object sender, System.EventArgs e) {
// создать новое множество данных (DataSet)
DataSet ds=new DataSet("XMLProducts");
//считать документ Xml в Dataset
ds.ReadXml("..\\..\\..\\prod.xml");
//загрузить данные в таблицу
detaGrid1.DataSource=ds;
dataGrid1.DataMember="products";
//создать новый XmlDataDocument
doc=new XmlDataDocument(ds);
//загрузить имена продуктов в окно списка
XmlNodeList nodeLst=doc.SelectNodes("//ProductName");
foreach(XmlNode nd in nodeLst) listBox1.Items.Add(nd.InnerXml);
}
Действительно, просто. Создается экземпляр нового объекта DataSet. Вызывается метод ReadXml, и XML оказывается в DataTableв DataSet. Как и методы WriteXml, ReadXmlимеет параметр XmlReadModeи пару дополнительных опций в XmlReadMode. Они приводятся в следующей таблице:
| Имя перечисления | Описание |
|---|---|
Auto |
Задает для XmlReadModeнаиболее подходящее значение. Если данные находятся в формате DiffGram, выбирается DiffGram. Если схема уже была прочитана, или если обнаружена подставляемая схема, то выбирается ReadSchema. Если с DataSet не связано ни одной схемы и не обнаружена подставляемая схема, то выбирается IgnoreSchema. |
DiffGram |
Считывает в документ DiffGramи применяет изменения к DataSet. DiffGramописан далее в этой главе. |
Fragment |
Считывает документы, которые содержат фрагменты схемы XDR, такие как тип, созданный SQL Server. |
IgnoreSchema |
Игнорирует подставляемую схему, которая может быть обнаружена. Считывает данные в текущую схему DataSet. Если данные не соответствуют схеме DataSet, они отбрасываются. |
InferSchema |
Игнорирует любую подставляемую схему. Создает схему на основе данных в документе XML. Если она существует в DataSet, используется эта схема, расширяемая дополнительными столбцами и таблицами. Если столбец существует, но имеет другой тип данных, порождается исключение. |
ReadSchema |
Считывает подставляемую схему и загружает данные. Не будет перезаписывать схему в DataSet, но будет порождать исключение, если таблица в подставляемой схеме уже существует в DataSet. |
Существует также метод ReadSchema. Он будет считывать автономную схему и создавать таблицы, столбцы и отношения соответственно. Этот метод используется, если схема не поставляется вместе с данными. ReadSchemaимеет те же четыре перегружаемые версии, строку с именем файла и путем доступа, объект на основе Stream, объектна основе TextReaderи объект на основе XmlReader.
Интервал:
Закладка:
Похожие книги на «C# для профессионалов. Том II»
Представляем Вашему вниманию похожие книги на «C# для профессионалов. Том II» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «C# для профессионалов. Том II» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.