Скотт Мейерс - Эффективное использование STL
Здесь есть возможность читать онлайн «Скотт Мейерс - Эффективное использование STL» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: СПб., Год выпуска: 2002, ISBN: 2002, Издательство: Питер, Жанр: Программирование, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.
- Название:Эффективное использование STL
- Автор:
- Издательство:Питер
- Жанр:
- Год:2002
- Город:СПб.
- ISBN:5-94723-382-7
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Эффективное использование STL: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Эффективное использование STL»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Во многих книгах описываются возможности STL, но только в этой рассказано о том, как работать с этой библиотекой. Каждый из 50 советов книги подкреплен анализом и убедительными примерами, поэтому читатель не только узнает, как решать ту или иную задачу, но и когда следует выбирать то или иное решение — и почему именно такое.
Эффективное использование STL — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Эффективное использование STL», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Совет 15. Помните о различиях в реализации string
Бьерн Страуструп однажды написал статью с интригующим названием «Sixteen Ways to Stack a Cat» [27], в которой были представлены разные варианты реализации стеков. Оказывается, по количеству возможных реализаций контейнеры stringне уступают стекам. Конечно, нам, опытным и квалифицированным программистам, положено презирать «подробности реализации», но если Эйнштейн был прав, и Бог действительно проявляется в мелочах… Даже если подробности действительно несущественны, в них все же желательно разбираться. Только тогда можно быть полностью уверенным в том, что они действительно несущественны.
Например, сколько памяти занимает объект string? Иначе говоря, чему равен результат sizeof(string)? Ответ на этот вопрос может быть весьма важным, особенно если вы внимательно следите за расходами памяти и думаете о замене низкоуровневого указателя char*объектом string.
Оказывается, результат sizeof(string)неоднозначен — и если вы действительно следите за расходами памяти, вряд ли этот ответ вас устроит. Хотя у некоторых реализаций контейнер stringпо размеру совпадает с char*, так же часто встречаются реализации, у которой stringзанимает в семь раз больше памяти. Чем объясняются подобные различия? Чтобы понять это, необходимо знать, какие данные и каким образом будут храниться в объекте string.
Практически каждая реализация stringхранит следующую информацию:
• размерстроки, то есть количество символов;
• емкостьблока памяти, содержащего символы строки (различия между размером и емкостью описаны в совете 14);
• содержимоестроки, то есть символы, непосредственно входящие в строку.
Кроме того, в контейнере string может храниться:
• копия распределителя памяти. В совете 10 рассказано, почему это поле не является обязательным. Там же описаны странные правила, по которым работают распределители памяти.
Реализации string, основанные на подсчете ссылок, также содержат:
• счетчик ссылокдля текущего содержимого.
В разных реализациях stringэти данные хранятся по-разному. Для наглядности мы рассмотрим структуры данных, используемые в четырех вариантах реализации string. В выборе нет ничего особенного, все варианты позаимствованы из широко распространенных реализаций STL. Просто они оказались первыми, попавшимися мне на глаза.
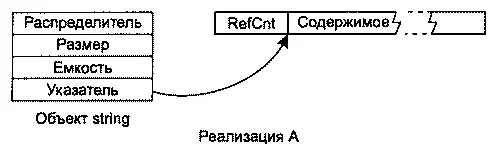
В реализации A каждый объект stringсодержит копию своего распределителя памяти, размер строки, ее емкость и указатель на динамически выделенный буфер со счетчиком ссылок ( RefCnt) и содержимым строки. В этом варианте объект string, использующий стандартный распределитель памяти, занимает в четыре раза больше памяти по сравнению с указателем. При использовании нестандартного указателя объект stringувеличится на размер объекта распределителя.
В реализации B объекты stringпо размерам не отличаются от указателей, поскольку они содержат указатель на структуру. При этом также предполагается использование стандартного распределителя памяти. Как и в реализации A, при использовании нестандартного распределителя размер объекта stringувеличивается на размер объекта распределителя. Благодаря оптимизации, присутствующей в этом варианте, но не предусмотренной в варианте A, использование стандартного распределителя обходится без затрат памяти.
В объекте, на который ссылается указатель, хранится размер строки, емкость и счетчик ссылок, а также указатель на динамически выделенный буфер с текущим содержимым строки. Здесь же хранятся дополнительные данные, относящиеся к синхронизации доступа в многопоточных системах. К нашей теме они не относятся, поэтому на рисунке соответствующая часть структуры данных обозначена «Прочее».
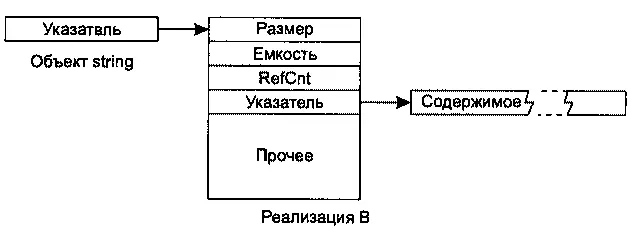
Блок «Прочее» оказался больше остальных блоков, поскольку я постарался выдержать масштаб изображения. Если один блок вдвое больше другого, значит, он занимает вдвое больше памяти. В реализации B размер данных синхронизации примерно в шесть раз превышает размер указателя.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Эффективное использование STL»
Представляем Вашему вниманию похожие книги на «Эффективное использование STL» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.









Обсуждение, отзывы о книге «Эффективное использование STL» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.