Александр Журавлев - ДИАЛОГ С КОМПЬЮТЕРОМ
Здесь есть возможность читать онлайн «Александр Журавлев - ДИАЛОГ С КОМПЬЮТЕРОМ» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 1987, Издательство: МОЛОДАЯ ГВАРДИЯ, Жанр: Программирование, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:ДИАЛОГ С КОМПЬЮТЕРОМ
- Автор:
- Издательство:МОЛОДАЯ ГВАРДИЯ
- Жанр:
- Год:1987
- Город:Москва
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
ДИАЛОГ С КОМПЬЮТЕРОМ: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «ДИАЛОГ С КОМПЬЮТЕРОМ»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
ДИАЛОГ С КОМПЬЮТЕРОМ — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «ДИАЛОГ С КОМПЬЮТЕРОМ», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Однако самая большая разница в информативности звуков слова вызвана обстоятельством, которое мы, казалось бы, не замечаем, а именно — разницей в частотности, или встречаемости, звукобукв в речи. Опять-таки, как и часто повторяющиеся события становятся обычными, теряют информативность, как слова от частого повторения «в привычку входят, ветшают, как платье», так и часто встречающиеся в речи звуки тоже оказываются малоинформативными, не задерживают на себе внимания, а значит, и незначительно влияют на восприятие слова, на формирование его фоносемантического ореола.
Редкие события высокоинформативны, они останавливают на себе внимание, выделяются из общего потока. И если в слове встречается редкий звук, он переключает на себя внимание воспринимающего, его содержательность становится доминирующей. И чем больше разница в частоте встречаемости между частыми и редкими звуками слова, тем выше информативность редких звуков, тем больше нужно увеличивать вес их средних оценок по сравнению со средними оценками остальных звуков.
Все эти расчеты компьютер выполнит легко, но ему для этого нужны данные об употребительности звукобукв. Те сведения, которые имелись в печати, не совсем подходили — ведь нужны данные именно о звукобуквах, а не о звуках или о буквах, да еще и отдельно по ударным и безударным гласным, да еще в какой-то нейтральной «усредненной» речи. Пришлось вести подсчеты по разным текстам, записывать на диктофоны разговорную речь в разных ситуациях. Работа большая, однообразная, изнурительная. Но что делать, других путей не было.
Забегая вперед, следует сказать, что теперь и эту работу смог бы выполнить сам компьютер. Когда мы перешли от отдельных слов к целым текстам (о чем будет рассказано ниже), компьютер все равно подсчитывал вероятности звукобукв. Не удержусь и похвастаю: компьютерные подсчеты, проведенные на гигантском материале, мало что изменили в наших данных, полученных вручную тяжелым трудом на выборках несравненно более скромного размера. Но это так, к слову, и не в укор машине. Ведь сколько времени и сил пришлось потратить на эту в общем-то подсобную, подготовительную работу! А компьютер выполнил ее походя, играючи.
Но наконец готово все. Многократно выверена, уточнена и перепроверена основная таблица, содержащая средние оценки всех русских звукобукв по 20 признаковым шкалам. Готова и таблица вероятностей звукобукв. Теперь слово за компьютером. Вот тут уж с ним вручную не потягаешься. Ручной расчет фоносемантического ореола даже для одного слова по всем шкалам — дело длинное, а печать машины стрекочет безостановочно, успевай только перфокарты загружать. А если работать с дисплеем, то время расчета — это фактически время набора слова на алфавитной клавиатуре. Иначе говоря, компьютер, как и человек, моментально «схватывает» фоносемантику слова.
Для тех, кому нравится более строгое изложение схемы вычислений, приведем формулы, по которым работает компьютер.
Если частотность (вероятность) любого ( i -того) звука слова обозначить как Р i , а максимальную частотность звука в данном слове как Р max , то коэффициент, учитывающий разницу частотностей звуков слова k i , можно вычислить как отношение:
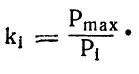
Теперь нужно учесть место каждого звука в слове. Для этого коэффициент первого звука слова (k i ) увеличим в четыре раза:
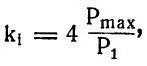
а для ударного (К уд ) — в два раза:
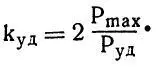
После этих приготовлений напишем основную формулу:
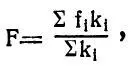
где F — фонетическая содержательность слова (его фоносемантика) ;
f i — фонетическая содержательность очередного (i-того) звука слова;
k i — коэффициент для очередного (i-того) звука слова;
Σ — знак суммы.
Последняя «примерка на манекенах» показывает, что все в порядке — схема расчета в общем верна. Информанты считают, что «слово» незич звучит как нечто «маленькое» и «нежное», а фрыш — как нечто «плохое, грубое, страшное», и компьютер дает примерно те же характеристики. По мнению информантов, хифель и уршух страшное, а лимень и нитис — безопасное; компьютер того же мнения. Вробар и вакам кажутся информантам сильными, и компьютер выдал для них тот же признак.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «ДИАЛОГ С КОМПЬЮТЕРОМ»
Представляем Вашему вниманию похожие книги на «ДИАЛОГ С КОМПЬЮТЕРОМ» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «ДИАЛОГ С КОМПЬЮТЕРОМ» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.