Алексей Валиков - Технология XSLT
Здесь есть возможность читать онлайн «Алексей Валиков - Технология XSLT» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Санкт-Петербург, Год выпуска: 2002, Издательство: БХВ-Петербург, Жанр: Программирование, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Технология XSLT
- Автор:
- Издательство:БХВ-Петербург
- Жанр:
- Год:2002
- Город:Санкт-Петербург
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Технология XSLT: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Технология XSLT»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Для начинающих и профессиональных программистов
Технология XSLT — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Технология XSLT», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Отметим также и то, что на практике некоторые из процессоров вообще не воссоздают внутреннюю модель документа, экономя, таким образом, ресурсы. Документы могут быть слишком объемными, и это препятствует загрузке их в память в виде древовидной структуры.
Некоторые из процессоров, напротив, используют DOM-модель документа для внутреннего представления обрабатываемой информации. Несмотря на большие требования к ресурсам памяти, такое решение также может иметь свои плюсы, например, универсальность и легкая интеграция в существующие XML-решения на базе DOM.
Но, так или иначе, с воссозданием древовидной структуры документа в памяти или нет, процессоры все равно оперируют одной и той же концептуальной моделью, которой мы сейчас и займемся.
Деревья
Прежде, чем мы приступим к рассмотрению типов узлов и отношений между ними, необходимо определиться с самой структурой дерева. Древовидная структура задает для своих элементов отношение ветвления, очень похожее на строение обычного дерева — есть корневой узел (ствол), от которого происходят другие узлы (ветки).
Формально [Кнут 2000] дерево определяется, как конечное множество T, состоящее из одного или нескольких элементов (узлов), обладающих следующими свойствами:
□ во множестве T выделяется единственный узел, называемый корневым узлом или корнем;
□ все остальные узлы разделены на m≥0 непересекающихся множеств T 1, …, T m, каждое из которых в свою очередь также является деревом.
Деревья T 1, …, T mназываются поддеревьями корня дерева T.
Это определение является рекурсивным, то есть в нем дерево определяется само через себя. Конечно, существуют нерекурсивные определения, но, пожалуй, следует согласиться с тем, что рекурсивное определение лучше всего отражает суть древовидной структуры: ветки дерева также являются деревьями.
В XSLT и XPath деревья являются упорядоченными, то есть для множеств T 1, …, T mзадается порядок следования, который называется порядком просмотра документа. В XSLT деревья упорядочиваются в порядке появления текстового представления их узлов в документах.
Существует множество способов графического изображения деревьев. Мы будем рисовать их так, что корень дерева будет находиться наверху, а поддеревья будут упорядочены слева направо. Такой способ является довольно стандартным для XML, хотя и здесь существует множество вариантов. Примером изображения дерева может быть следующий рисунок (рис. 3.2):
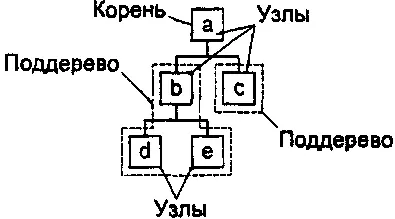
Рис. 3.2. Изображение дерева
Мы часто будем говорить о дочерних узлах, родительских узлах, братских узлах, узлах-предках и узлах-потомках. Дадим определения этим понятиям.
□ Дочерним узлом текущего узла называется любой из корней его поддеревьев. Например, в дереве на рис. 3.2 дочерними узлами узла аявляются узлы b и с, а дочерними узлами узла b— узлы dи e. Узел сне имеет дочерних узлов — такие узлы иначе называются листьями.
□ Каждый узел называется родительским узлом корней своих поддеревьев. На рис. 3.2 узел аявляется родителем узлов bи с, а узел b— родителем узлов dи e.
□ Корни поддеревьев называются братскими узлами или узлами-братьями. На рис. 3.2 братьями являются узлы bи с, а также узлы dи e.
□ Предками текущего узла являются его родитель, а также родители его родителей и так далее. На рис. 3.2 предками узла dявляются узлы bи а.
□ Потомками текущего узла являются его дочерние узлы, а также дочерние узлы его дочерних узлов и так далее. На рис. 3.2 потомками узла аявляются узлы b, c, dи e.
Узлы дерева XML-документа
Корневой узел
Корневой узел XML-документа — это узел, который является корнем дерева документа. Не следует путать его с корневым элементом документа, поскольку помимо корневого элемента дочерними узлами корня также являются инструкции по обработке и комментарии, которые находятся вне корневого элемента.
Мы будем помечать корневой узел документа символом " /" и изображать следующим образом (рис. 3.3):

Рис. 3.3. Изображение корневого узла
На рис. 3.4 показано изображение документа,
<���В/>
Интервал:
Закладка:
Похожие книги на «Технология XSLT»
Представляем Вашему вниманию похожие книги на «Технология XSLT» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Технология XSLT» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.