Алексей Валиков - Технология XSLT
Здесь есть возможность читать онлайн «Алексей Валиков - Технология XSLT» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Санкт-Петербург, Год выпуска: 2002, Издательство: БХВ-Петербург, Жанр: Программирование, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Технология XSLT
- Автор:
- Издательство:БХВ-Петербург
- Жанр:
- Год:2002
- Город:Санкт-Петербург
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Технология XSLT: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Технология XSLT»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Для начинающих и профессиональных программистов
Технология XSLT — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Технология XSLT», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
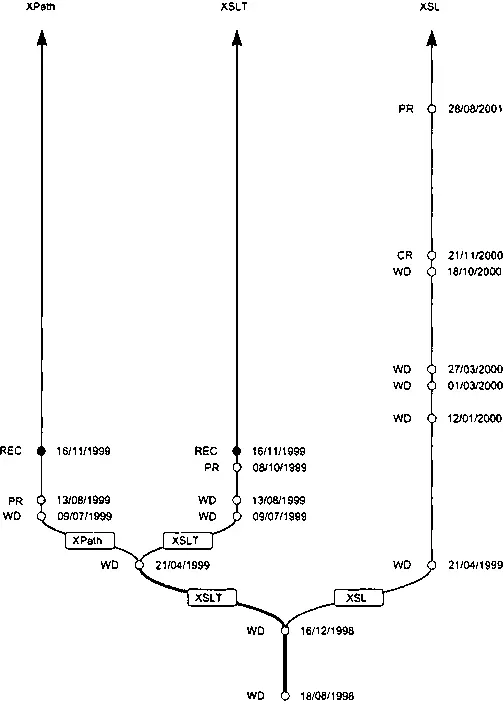
Рис. 2.12. История развития языка XSL в виде графа
Что касается XSLT и XPath, спецификации обоих этих языков стали техническими рекомендациями 16 ноября 1999 года. Сам же язык XSL, который теперь стали называть XSL-FO (аббревиатура FO означает formatting objects — форматирующие объекты), получил статус рекомендации не так быстро. Спустя год, в ноябре 2000, спецификация XSL получила статус кандидата в рекомендации, а еще через 9 месяцев с минимальными исправлениями — статус предлагаемой рекомендации. По всей видимости, к тому моменту, когда эта книга увидит свет, спецификация XSL уже будет официальной рекомендацией W3C.
Одного года было достаточно, чтобы XSLT стал широко использоваться во многих XSLT-задачах. Повышенное внимание разработчиков позволило выявить некоторые досадные огрехи, которые были допущены в первой версии XSLT, и потому в конце 2000 года была начата работа над версией 1.1. В новой версии рабочая группа XSL постаралась исправить большинство ошибок, допущенных в версии 1.0 и добавить некоторые возможности, которых не хватало в первой версии. Однако через некоторое время стало понятно, что разрабатываемый язык довольно сильно отличается от первой версии. К тому же, с учетом таких разработок, как XML Schema и XQuery возникла необходимость изменить модель данных и выражений XPath. В итоге, работу над версией 1.1 решено было прекратить и переключиться на создание вторых версий языков XSLT и XPath.
Вместо того чтобы разбирать в этой книге особенности версии 1.1, которая никогда не станет рекомендацией, в последней главе мы опишем то, что, согласно требованиям ко вторым версиям языков XSLT и XPath, ожидается в их спецификациях, и что, согласно XSLT 1.1 там точно будет. Работа над XSLT 2.0 и XPath 2.0 в самом разгаре: к сентябрю 2001 года были уже готовы три внутренних рабочих версии. К сожалению, открывать секреты рабочей группы XSL мы не в праве, хотя можно смело сказать, что процесс работы внушает оптимизм.
Глава 3
Идея и модель языка XSLT
Модель XML-документа
Описывая основы построения XML-документов, мы отмечали, что иерархическая организация информации в XML лучше всего описывается древовидными структурами. Дерево — это четкая, мощная и простая модель данных и именно она была на концептуальном уровне применена в языках XSLT и XPath. Как пишет Кнут [Кнут 2000], " деревья — это наиболее важные нелинейные структуры, которые встречаются при работе с компьютерными алгоритмами ". Добавим, что это без сомнения самая важная структура из тех, которыми оперируют языки XSLT и XPath.
В этих языках документ моделируется как дерево, состоящее из узлов. Узлы дерева соответствуют структурным единицам XML — элементам, атрибутам, тексту и так далее, а дуги, ветки — отношениям между этими единицами. Простейшим примером является принадлежность одних элементов другим. Документ вида
<���а>
<���с/>
</а>
может быть представлен деревом (рис. 3.1).
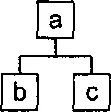
Рис. 3.1. Представление документа в виде дерева
Аналогия совершенно очевидна — элемент асодержит элементы bи с, в то время как в дереве вершина аявляется родительским узлом для вершин bи с.
Естественно, XML-документы состоят далеко не из одних только элементов и потому для того, чтобы дерево достоверно отражало структуру и содержание документа, в нем выделяются узлы следующих семи типов:
□ корневой узел;
□ узлы элементов;
□ узлы атрибутов;
□ текстовые узлы;
□ узлы пространств имен;
□ узлы инструкций по обработке;
□ узлы комментариев.
Каждый узел дерева имеет соответствующее ему строковое значение, которое вычисляется в зависимости от типа. Строковым значением корневого узла и узла элемента является конкатенация (строковое сложение) строковых значений всех их потомков, для остальных типов узлов строковое значение является частью самого узла. Порядок вычисления строковых значений узлов будет более детально определен в описании каждого из типов.
Мы подробно разберем каждый из типов узлов чуть позже, а пока отметим, что дерево в XSLT и XPath является чисто концептуальной моделью. Процессоры не обязаны внутренне представлять документы именно в этой структуре, концептуальная модель означает лишь то, что все операции преобразования над документами будут определяться в терминах деревьев. Для программиста же это означает, что вовсе необязательно вникать в тонкости реализации преобразований в том или ином процессоре. Все равно они должны работать, так, как будто они работают непосредственно с деревьями.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Технология XSLT»
Представляем Вашему вниманию похожие книги на «Технология XSLT» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Технология XSLT» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.