Алексей Валиков - Технология XSLT
Здесь есть возможность читать онлайн «Алексей Валиков - Технология XSLT» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Санкт-Петербург, Год выпуска: 2002, Издательство: БХВ-Петербург, Жанр: Программирование, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Технология XSLT
- Автор:
- Издательство:БХВ-Петербург
- Жанр:
- Год:2002
- Город:Санкт-Петербург
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Технология XSLT: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Технология XSLT»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Для начинающих и профессиональных программистов
Технология XSLT — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Технология XSLT», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Следуя спецификации, большинство реализаций XSLT предоставляет интерфейсы для разработки собственных функций, немного реже — элементов. Расширения пишутся на обычных языках программирования, таких как Java или С, но используются в XSLT так же, как использовались бы обычные функции и элементы.
Технология расширений делает XSLT поистине универсальным языком, ведь получается, что в нем можно использовать любые вычисления, которые только могут быть описаны в классических языках программирования.
К сожалению, вследствие различий в интерфейсах расширений, их использования приводит к потере переносимости между платформами и процессорами. Если преобразования, созданные в соответствии со стандартом языка, будут, как правило, без проблем выполняться различными процессорами, использование расширений в большинстве случаев ограничивает переносимость преобразования.
Преобразования снаружи
В общем случае в преобразовании участвуют три документа:
□ входящий документ , который подвергается преобразованию;
□ документ, который описывает само преобразование ;
□ выходящий документ , который является результатом преобразования.
Само по себе преобразование это всего лишь XML-документ, не более чем описание правил, в соответствии с которыми входящий документ должен трансформироваться в исходящий. Процесс преобразования входящего документа в соответствии с описанными правилами называется применением преобразования к входящему документу или просто выполнением данного преобразования.
Выполнением преобразований над документами занимаются специальные программы, которые называются XSLT-процессорами. В первом приближении схема преобразования приведена на рис. 2.1.
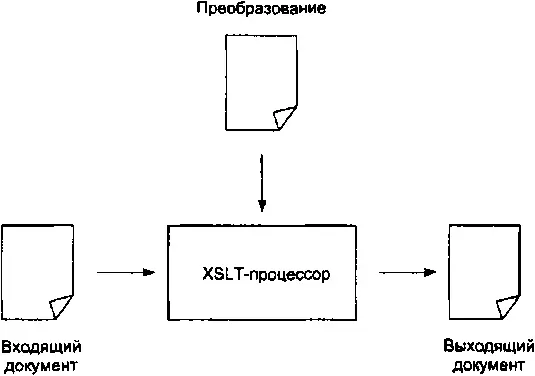
Рис. 2.1. Схема XSLT-преобразования
Процессор получает входящий документ и преобразование, и, применяя правила преобразования, генерирует выходящий документ — такова в общем случае внешняя картина. На самом деле процессор оперирует не самими документами, а древовидными моделями их структур (рис. 2.2.) — именно структурными преобразованиями занимается XSLT, оставляя за кадром синтаксис, который эти структуры выражает.
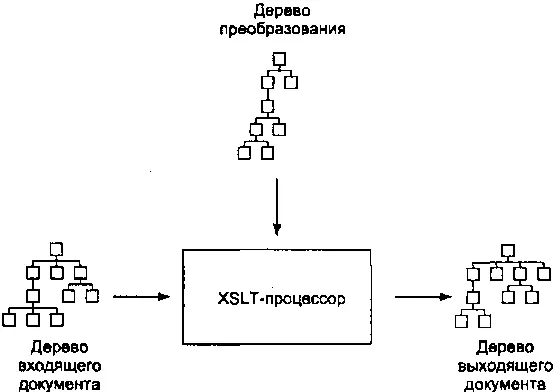
Рис. 2.2.Древовидные структуры в XSLT
Несмотря на то, что для XSLT как для языка совершенно неважно, в каком виде находятся документы изначально (главное — чтобы была структура, которую можно преобразовать), абсолютное большинство процессоров может работать с документами, которые физически записаны в файлах. В этом случае процесс обработки делится на три стадии.
□ XSLT-процессор разбирает входящий документ и документ преобразования, создавая для них древовидные структуры данных. Этот этап называется этапом парсинга документа (от англ. parse — разбирать).
□ К дереву входящего документа применяются правила, описанные в преобразовании. В итоге процессор создает дерево выходящего документа. Этот этап называется этапом преобразования .
□ Для созданного дерева генерируется физическая сущность. Этот этап называется этапом сериализации .
Хотя практически все процессоры выполняют каждый из этих трех этапов (получают входящие документы и выдают результат их трансформации), рабочей областью XSLT является только второй этап, этап преобразования. XSLT практически не контролирует парсинг входящего документа, как правило, этим занимается встроенный или внешний SAX- или DOM-парсер.
С сериализацией дела обстоят немного сложнее. С точки зрения преобразования, результирующее дерево — это все, что от него требуется, но вряд ли разработчику будет этого достаточно. Редко когда сгенерированная абстрактная древовидная структура — это то, что нужно. Гораздо чаще результат преобразования требуется получить в определенной физической форме.
Сериализация как раз и является процессом создания физической интерпретации результирующего дерева, и если и эта задача делегируется XSLT-процессору, то преобразованию под силу контролировать физический вывод генерируемого документа (рис. 2.3).
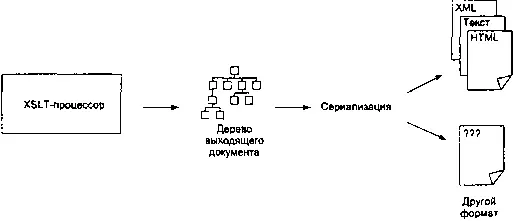
Рис. 2.3. Сериализация в XSLT
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Технология XSLT»
Представляем Вашему вниманию похожие книги на «Технология XSLT» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Технология XSLT» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.