Джулиан Бакнелл - Фундаментальные алгоритмы и структуры данных в Delphi
Здесь есть возможность читать онлайн «Джулиан Бакнелл - Фундаментальные алгоритмы и структуры данных в Delphi» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Год выпуска: 2003, ISBN: 2003, Издательство: ДиаСофтЮП, Жанр: Программирование, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Фундаментальные алгоритмы и структуры данных в Delphi
- Автор:
- Издательство:ДиаСофтЮП
- Жанр:
- Год:2003
- ISBN:ISBN 5-93772-087-3
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Фундаментальные алгоритмы и структуры данных в Delphi: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Фундаментальные алгоритмы и структуры данных в Delphi»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
В книге подробно рассматриваются базовые понятия алгоритмов и основополагающие структуры данных, алгоритмы сортировки, поиска, хеширования, синтаксического разбора, сжатия данных, а также многие другие темы, тесно связанные с прикладным программированием. Изобилие тщательно проверенных примеров кода существенно ускоряет не только освоение фундаментальных алгоритмов, но также и способствует более квалифицированному подходу к повседневному программированию.
Несмотря на то что книга рассчитана в первую очередь на профессиональных разработчиков приложений на Delphi, она окажет несомненную пользу и начинающим программистам, демонстрируя им приемы и трюки, которые столь популярны у истинных «профи». Все коды примеров, упомянутые в книге, доступны для выгрузки на Web-сайте издательства.
Фундаментальные алгоритмы и структуры данных в Delphi — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Фундаментальные алгоритмы и структуры данных в Delphi», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Какие значения к лучше всего использовать? Шелл в своей первой статье на эту тему предложил значения 1, 2, 4, 8, 16, 32 и т.д. (естественно, в обратном порядке), но с этими значениями связана одна проблема: до последнего прохода элементы с четными индексами никогда не сравниваются с элементами с нечетными индексами. И, следовательно, при выполнении последнего прохода все еще возможны перемещения элементов на большие расстояния (представьте себе, например, искусственный случай, когда элементы с меньшими значениями находятся в позициях с четными индексами, а элементы с большими значениями - в позициях с нечетными индексами).
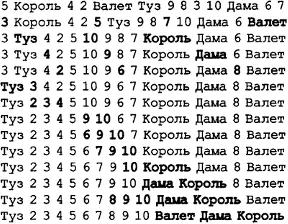
Рисунок 5.6. Сортировка методом Шелла
В 1969 году Дональд Кнут (Donald Knuth) предложил последовательность 1, 4, 13, 40, 121 и т.д. (каждое последующее значение на единицу больше, чем утроенное предыдущее значение). Для списков средних размеров эта последовательность позволяет получить достаточно высокие характеристики быстродействия (на основе эмпирических исследований Кнут оценил быстродействие для среднего случая как O(n(^5/4^)), а для худшего случая было доказано, что скорость работы равна O(n(^3/2^))) при несложном методе вычисления значений самой последовательности. Ряд других последовательностей позволяют получить более высокие значения скорости работы (хотя и не намного), но требуют предварительного вычисления значений последовательности, поскольку используемые формулы достаточно сложны. В качестве примера можно привести самую быструю известную на сегодняшний день последовательность, разработанную Робертом Седжвиком (Robert Sedgewick): 1, 5, 19, 41, 109 и т.д. (формируется путем слияния двух последовательностей — 9 * 4i - 9 * 2i + 1 для i > 0 и 4i - 3 * 2i + 1 для i > 1). Известно, что для этой последовательности время работы в худшем случае определяется как O(n(^4/3^)) при O(n(^7/6^)) для среднего случая. В этой книге мы не будем приводить математические выкладки для определения приведенных зависимостей. Пока не известно, существуют ли еще более быстрые последовательности. (подробнейшие выкладки и анализ всех фундаментальных алгоритмов, в числе которых и алгоритмы, рассмотренные в данной книге, а также эффективная их реализация на языках С, С++ и Java, можно найти в многотомниках Роберта Седжвика "Фундаментальные алгоритмы на С++", "Фундаментальные алгоритмы на С" и "Фундаментальные алгоритмы на Java", которые выпущены издательством "Диасофт".)
Листинг 5.9. Сортировка методом Шелла при использовании последовательности Кнута
procedure TDShellSort(aList : TList;
aFirst : integer;
aLast : integer;
aCompare : TtdCompareFunc);
var
i, j : integer;
h : integer;
Temp : pointer;
Ninth : integer;
begin
TDValidateListRange(aList, aFirst, aLast, 'TDShellSort');
{прежде всего вычисляем начальное значение h; оно должно быть близко к одной девятой количества элементов в списке}
h := 1;
Ninth := (aLast - aFirst) div 9;
while (h<= Ninth) do h := (h * 3) + 1;
{начать выполнение цикла, который при каждом проходе уменьшает значение h на треть}
while (h > 0) do
begin
{выполнить сортировку методом вставки для каждого подмножества}
for i := (aFirst + h) to aLast do
begin
Temp := aList.List^[i];
j := i;
while (j >= (aFirst+h)) and
(aCompare(Temp, aList.List^[j-h]) < 0) do
begin
aList.List^[j] := aList.List^[j-h];
dec(j, h);
end;
aList.List^[j ] := Teilend;
{уменьшить значение h на треть}
h := h div 3;
end;
end;
Математические зависимости для анализа быстродействия сортировки методом Шелла достаточно сложны. В общем случае для оценки времени выполнения сортировки при различных значениях h приходится ограничиваться статистическими данными. Тем не менее, анализ быстродействия алгоритма Шелла практически не имеет смысла, поскольку существуют более быстрые алгоритмы.
Что касается устойчивости, то при перестановке элементов, далеко отстоящих друг от друга, возможно нарушение порядка следования элементов с равными значениями. Следовательно, сортировка методом Шелла относится к группе неустойчивых алгоритмов.
Сортировка методом прочесывания
Этот раздел будет посвящен действительно странному алгоритму сортировки -сортировке методом прочесывания (comb sort). Он не относится к стандартным алгоритмам. На сегодняшний день он малоизвестен и поиск информации по нему может не дать никаких результатов. Тем не менее, он отличается достаточно высоким уровнем быстродействия и удобной реализацией. Метод был разработан Стефаном Лейси (Stephan Lacey) и Ричардом Боксом (Richard Box) и опубликован в журнале "Byte" в апреле 1991 года. Фактически он использует пузырьковую сортировку таким же образом, как сортировка методом Шелла использует сортировку методом вставок.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Фундаментальные алгоритмы и структуры данных в Delphi»
Представляем Вашему вниманию похожие книги на «Фундаментальные алгоритмы и структуры данных в Delphi» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Фундаментальные алгоритмы и структуры данных в Delphi» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.