Олег Цилюрик - QNX/UNIX - Анатомия параллелизма
Здесь есть возможность читать онлайн «Олег Цилюрик - QNX/UNIX - Анатомия параллелизма» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Санкт-Петербург, Год выпуска: 2006, ISBN: 2006, Издательство: Символ-Плюс, Жанр: Программирование, ОС и Сети, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:QNX/UNIX: Анатомия параллелизма
- Автор:
- Издательство:Символ-Плюс
- Жанр:
- Год:2006
- Город:Санкт-Петербург
- ISBN:5-93286-088-Х
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
QNX/UNIX: Анатомия параллелизма: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «QNX/UNIX: Анатомия параллелизма»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
В качестве «испытательной площадки» для тестовых фрагментов выбрана ОСРВ QNX, что позволило с единой точки зрения взглянуть как на специфические механизмы микроядерной архитектуры QNX, так и на универсальные механизмы POSIX. В этом качестве книга может быть интересна и тем, кто не использует (и не планирует никогда использовать) ОС QNX: программистам в Linux, FreeBSD, NetBSD, Solaris и других традиционных ОС UNIX.
QNX/UNIX: Анатомия параллелизма — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «QNX/UNIX: Анатомия параллелизма», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
• Объекты, время жизни которых определяется ядром системы (kernel-persistent). Такой объект существует до перезагрузки ядра или явного удаления объекта. Примерами этого класса объектов являются семафоры (именованные) и разделяемая память.
• Объекты, время жизни которых определяется файловой системой (filesystem-persistent). Такой объект отображается на файловую систему и существует до тех пор, пока не будет явно удален. Примерами этого класса объектов в различных ОС в зависимости от реализации могут быть очереди сообщений POSIX, семафоры и разделяемая память.
Квалификация каждого из объектов по времени жизни отнюдь не тривиальная задача. Объекты, отнесенные к одному классу, мигрируют в другой при переходе от одной ОС к другой в зависимости от деталей их реализации.
Проблемы завершения и особенно отмены процесса могут возникать, если процесс оперирует с объектами, время жизни которых превышает process-persistent. Мы еще много раз коснемся этой проблемы при рассмотрении завершения потоков, так как там она может возникать и в отношении всех process-persistent-объектов, и для ее разрешения в технике потоков даже предложены специальные технологии, о которых мы детально поговорим далее, при рассмотрении потоков.
Соображения производительности
Интересны не только затраты на порождение нового процесса (мы еще будем к ним неоднократно возвращаться), но и то, насколько «эффективно» сосуществуют параллельные процессы в ОС, насколько быстро происходит переключение контекста с одного процесса на другой. Для самой грубой оценки этих затрат создадим простейшее приложение ( файл p5.cc ):
#include
#include
#include
#include
#include
#include
int main(int argc, char* argv[]) {
unsigned long N = 1000;
if (argc > 1 && atoi(argv[1]) > 0)
N = atoi(argv[1]);
pid_t pid = fork();
if (pid == -1)
cout << "fork error" << endl, exit(EXIT_FAILURE);
uint64_t t = ClockCycles();
for (unsigned long i = 0; i < N; i++) sched_yield();
t = ClockCycles() - t;
delay(200);
cout << pid << "\t: cycles - " << t << "; on sched - " << (t/N) / 2 << endl;
exit(EXIT_SUCCESS);
}
Два одновременно выполняющихся процесса настолько симметричны и идентичны, что они даже не анализируют PID после выполнения fork(), они только в максимальном темпе «перепасовывают» друг другу активность, как волейболисты делают это с мячом (рис. 2.2).
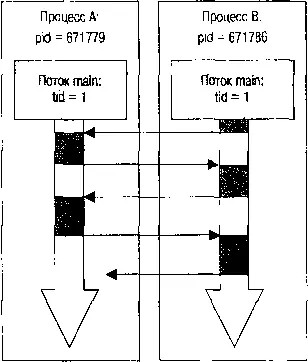
Рис. 2.2. Симметричное взаимодействие потоков
Рисунок 2.2 иллюстрирует взаимодействие двух идентичных процессов: вся их «работа» состоит лишь в том, чтобы как можно быстрее передать управление партнеру. Такую схему, когда два и более как можно более идентичных потоков или процессов в максимально высоком темпе (на порядок превосходящем последовательность «естественной» RR-диспетчеризации) обмениваются активностью, мы будем неоднократно использовать в дальнейшем для различных механизмов, называя ее для простоты «симметричной схемой».
Чтобы максимально упростить код приложения, при его написании мы не трогали события «естественной» диспетчеризации, имеющие место при RR-диспетчеризации каждые 4 системных тика (по умолчанию это ~4 миллисекунды). Как сейчас покажут результаты, события принудительной диспетчеризации происходят с периодичностью порядка 1 микросекунды, т.e. в 4000 раз чаще, и возмущения, возможно вносимые RR-диспетчеризацией, можно считать не настолько существенными.
Вот результаты выполнения этой программы:
# nice -n-19 p5 1000000
1069102 : cycles - 1234175656; on sched — 617
0 : cycles - 1234176052; on sched - 617
# nice -n-19 p5 100000
1003566 : cycles - 123439225; on sched — 617
0 : cycles - 123440347; on sched - 617
# nice -n-19 p5 10000
1019950 : cycles - 12339084; on sched — 616
0 : cycles - 12341520; on sched - 617
# nice -n-19 p5 1000
1036334 : cycles - 1243117; on sched — 621
0 : cycles - 1245123; on sched - 622
# nice -n-19 p5 100
1052718 : cycles - 130740; on sched — 653
0 : cycles - 132615; on sched - 663
Видна на удивление устойчивая оценка, практически не зависящая от общего числа актов диспетчеризации, изменяющегося на 4 порядка.
Отбросив мелкие добавки, привносимые инкрементом и проверкой счетчика цикла, можно считать, что передача управления от процесса к процессу требует порядка 600 циклов процессора (это порядка 1,2 микросекунды на компьютере 533 МГц, на котором выполнялся этот тест).
Читать дальшеИнтервал:
Закладка:
Похожие книги на «QNX/UNIX: Анатомия параллелизма»
Представляем Вашему вниманию похожие книги на «QNX/UNIX: Анатомия параллелизма» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.










Обсуждение, отзывы о книге «QNX/UNIX: Анатомия параллелизма» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.