Роб Кёртен - Введение в QNX/Neutrino 2. Руководство по программированию приложений реального времени в QNX Realtime Platform
Здесь есть возможность читать онлайн «Роб Кёртен - Введение в QNX/Neutrino 2. Руководство по программированию приложений реального времени в QNX Realtime Platform» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Санкт-Петербург, Год выпуска: 2001, ISBN: 2001, Издательство: Петрополис, Жанр: Программирование, ОС и Сети, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.
- Название:Введение в QNX/Neutrino 2. Руководство по программированию приложений реального времени в QNX Realtime Platform
- Автор:
- Издательство:Петрополис
- Жанр:
- Год:2001
- Город:Санкт-Петербург
- ISBN:5-94656-025-9
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Введение в QNX/Neutrino 2. Руководство по программированию приложений реального времени в QNX Realtime Platform: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Введение в QNX/Neutrino 2. Руководство по программированию приложений реального времени в QNX Realtime Platform»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
В книге подробно описаны основные составляющие ОС QNX/Neutrino и их взаимосвязи. В частности, уделено особое внимание следующим темам:
• обмен сообщениями: принципы функционирования и основы применения;
• процессы и потоки: базовые концепции, предостережения и рекомендации;
• таймеры: организация периодических событий в программах;
• администраторы ресурсов: все, что относится к программированию драйверов устройств;
• прерывания: рекомендации по эффективной обработке.
В книге представлено множество проверенных примеров кода, подробных разъяснений и рисунков, которые помогут вам детально вникнуть в и излагаемый материал. Примеры кода и обновления к ним также можно найти на веб-сайте автора данной книги, www.parse.com.
Введение в QNX/Neutrino 2. Руководство по программированию приложений реального времени в QNX Realtime Platform — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Введение в QNX/Neutrino 2. Руководство по программированию приложений реального времени в QNX Realtime Platform», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
(Функция writeblock() описывается аналогично.)
Вы можете вообразить для функции readblock() довольно «простенькую» реализацию:
int readblock(int fd, size_t blksize, unsigned block,
int numblks, void *buff) {
lseek(fd, blksize * block, SEEK_SET); // Идем к блоку
read(fd, buff, blksize * numblks);
}
Очевидно, что от такой реализации в многопоточной среде толку мало. Нам нужно будет как минимум добавить использование мутекса:
int readblock(int fd, size_t blksize, unsigned block,
int numblks, void *buff) {
pthread_mutex_lock(&block_mutex);
lseek(fd, blksize * block, SEEK_SET); // Идем к блоку
read(fd, buff, blksize * numblks);
pthread_mutex_unlock(&block_mutex);
}
(Мы здесь предполагаем, что мутекс уже инициализирован.)
Этот код по-прежнему уязвим для «незащищенного» доступа — если некий поток вызовет lseek() на этом файловом дескрипторе без предварительной попытки захвата мутекса, вот у нас уже и ошибка.
Решение проблемы заключается в использовании составного сообщения, аналогично вышеописанному случаю с функцией chown() . В данном случае библиотечная реализация функции readblock() помещает обе операции — lseek() и read() — в единое сообщение и посылает это сообщение администратору ресурсов:

Составное сообщение для функции readblock() .
Это работает, потому что передача сообщения является атомарной операцией. С точки зрения клиента, сообщение уходит либо целиком, либо не уходит вообще. Поэтому, вмешательство «незащищенной» функции lseek() становится несущественным — когда администратор ресурсов принимает сообщение с запросом readblock() , он делает это за один прием. (Очевидно, что в этом случае пострадает сама «незащищенная» lseek() , поскольку после отработки readblock() смещение на этом дескрипторе файла будет отличаться от того, которое она хотела установить.)
А как насчет самого администратора ресурсов? Как он обрабатывает операцию readblock() за один прием? Мы вскоре рассмотрим это, когда будем обсуждать операции, выполняемые для каждого компонента составных сообщений.
Структуры данных уровня POSIX
К подпрограммам POSIX-уровня относятся три структуры данных. Отметьте, что пока речь идет о базовом уровне , вы можете использовать любые структуры данных, которые пожелаете; соответствия определенной структуре и содержанию требует именно уровень POSIX. Однако, преимущества, которые предоставляет POSIX-уровень, с лихвой окупают вносимые ограничения. Как мы увидим далее, вы также сможете дополнять эти структуры вашим собственным содержанием.
На рисунке приведены эти три структуры данных для случая, когда несколько клиентов используют администратора ресурсов, объявивший два устройства:
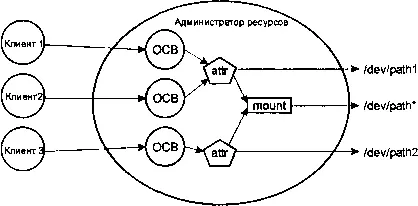
Структуры данных — общая схема.
Структурами данных являются:
iofunc_ocb_t — OCB (блок открытого контекста)
Содержит информацию по каждому дескриптору файла.
iofunc_attr_t — атрибутная запись
Содержит информацию по каждому устройству.
iofunc_mount_t — запись точки монтирования
Содержит информацию по каждой точке монтирования.
Когда мы обсуждали таблицы функций установления соединения и ввода/вывода, мы уже видели блоки открытого контекста и атрибутные записи — в таблицах функций ввода/вывода OCB был последним передаваемым параметром. Атрибутная запись передавалась как параметр handle (третий по счету) в функциях установления соединения. Запись точки монтирования обычно представляет собой глобальную структуру и привязывается к атрибутной записи «вручную» (в инициализационном коде, написанном вами для вашего администратора ресурса).
iofunc_ocb_tСтруктура блока открытого контекста (OCB) содержит информацию по каждому дескриптору файла. Это означает, что когда клиент выполняет вызов open() и получает в ответ дескриптор файла (в противоположность коду ошибки), администратор ресурсов создает OCB и связывает его с данным клиентом. Этот OCB будет существовать до тех пор, пока клиент держит данный дескриптор файла открытым. В действительности, OCB и дескриптор файла — всегда согласованная пара. По каждому сообщению ввода/вывода от клиента библиотека администратора ресурсов автоматически ищет нужный OCB и вместе с сообщением передает его нужной функции из таблицы функций ввода/вывода. Это ответ на вопрос, зачем всем функциям ввода/вывода параметр ocb . В конце концов клиент закроет дескриптор файла (применив close() ), что заставит администратор ресурса отвязать OCB от дескриптора файла и от клиента. Заметьте, что клиентская функция dup() просто увеличивает счетчик связей. В этом случае OCB отделяется от дескриптора файла и от клиента только тогда, когда значение счетчика связей достигнет нуля (то есть когда число вызовов close() будет соответствовать числу open() и dup() ).
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Введение в QNX/Neutrino 2. Руководство по программированию приложений реального времени в QNX Realtime Platform»
Представляем Вашему вниманию похожие книги на «Введение в QNX/Neutrino 2. Руководство по программированию приложений реального времени в QNX Realtime Platform» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.









Обсуждение, отзывы о книге «Введение в QNX/Neutrino 2. Руководство по программированию приложений реального времени в QNX Realtime Platform» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.