Компьютерра - Журнал «Компьютерра» № 11 от 20 марта 2007 года
Здесь есть возможность читать онлайн «Компьютерра - Журнал «Компьютерра» № 11 от 20 марта 2007 года» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: Прочая околокомпьтерная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Журнал «Компьютерра» № 11 от 20 марта 2007 года
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Журнал «Компьютерра» № 11 от 20 марта 2007 года: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Журнал «Компьютерра» № 11 от 20 марта 2007 года»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Журнал «Компьютерра» № 11 от 20 марта 2007 года — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Журнал «Компьютерра» № 11 от 20 марта 2007 года», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
На наши вопросы о теории и практике датамайнинга ответил Григорий Пятецкий-Шапиро (Gregory Piatetsky-Shapiro), основатель и председатель SIGKDD - Группы особых интересов, посвященной "открытию знаний в данных" (Knowledge Discovery in Data).
ОЦЕНКА
Удачные статистические модели позволили выявить потенциальные "налоговые убежища" обеспеченных американцев объемом в сотни миллионов долларов.
Какие новые разделы датамайнинга (ДМ) появились в последние годы? Какие из них самые перспективные для бизнеса, для исследовательской работы?
- Одно из замечательных новых полей исследований - анализ связей (link analysis). Приложения весьма обширны, от биоинформатики до выявления преступлений, от маркетинга до исследования социальных сетей. Вокруг Web 2.0 сейчас столько шума именно потому, что он очень эффективно использует веб как инструмент социальных связей, - а это придает все большую значимость анализу этих связей.
Огромный прогресс виден и в майнинге текста (большинство программных комплексов [suites] для датамайнинга теперь включают компоненты для текст-майнинга), а также в майнинге мультимедиа. И то и другое - прекрасные области для исследований.
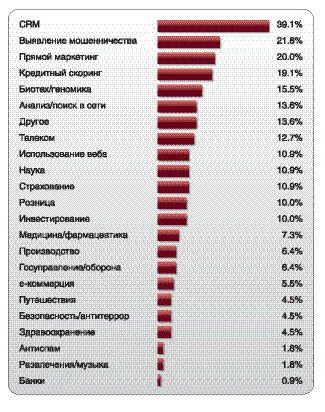
Датамайнинг широко применяется в больших компаниях, особенно работающих в электронной коммерции. Amazon, Yahoo - примеры таких компаний (мой коллега Усама Файяд занимает должность руководителя по обработке данных [Chief Data Officer] в Yahoo, он первым в индустрии е-коммерции получил такой титул). Вот неполный список областей применения датамайнинга:
• реклама;
• биоинформатика;
• связь с клиентами (CRM);
• маркетинг;
• выявление мошенничества (fraud detection);
• е-коммерция;
• здравоохранение;
• инвестиции/ценные бумаги;
• управление производством;
• развлечения и спорт;
• телекоммуникации;
• изучение веба.
Если говорить об успехах индустрии датамайнинга, то самый яркий пример здесь - Google. Oба его сооснователя в Стэнфорде занимались исследованиями в этой области, и ранняя история самого Google связана с датамайнингом.
Рекомендации на сайте Amazon.com ("покупатели, купившие/искавшие/посмотревшие X, купили также Z") привели к огромному росту продаж. Высококачественные рекомендации такого типа обеспечили успех компании Netflix, занимающейся прокатом видео.
Например, если вам понравилась знаменитая абсурдистская комедия "Монти Пайтон и священный Грааль" ("Monty Python and the Holy Grail"), то вы получите от Netflix рекомендацию посмотреть "This is Spinal Tap" ["Пункция спинномозговой жидкости"], известную пародию на документальный фильм о гастролях экстравагантной рок-группы. Netflix придает такое значение датамайнингу, что в прошлом году учредила приз в миллион долларов за улучшение алгоритма выработки рекомендаций (см. врезку).
Как развивалась ваша карьера? Как вы заинтересовались датамайнингом?
- С детства у меня была склонность к математике, очевидно унаследованная от папы, крупного математика Ильи Пятецкого-Шапиро. Живя в Москве, я учился в известной Второй математической школе, принимал участие в математических олимпиадах - но поскольку перенял от папы лишь малую часть математического таланта, то уже в школе понял, что чистая математика не для меня. Я открыл для себя компьютеры в 1974 году, на первом курсе в Технионе, когда эмигрировал в Израиль, и сразу заинтересовался ими. Меня особенно увлекали вопросы искусственного интеллекта. Первую интересную программу я написал в 1974 году на языке АПЛ - она была предназначена для игры в "морской бой". Сыграв с ней одну партию, я безоговорочно уступил своей же программе. Желание продолжать игру исчезло - зато усилилось желание писать программы. Потом была учеба в аспирантуре в США, тоже с концентрацией на задачах искусственного интеллекта. Темой диссертации стало приложение искусственного интеллекта к работе с базами данных.
Датамайнингом я заинтересовался, работая в Лабораториях GTE (организация, подобная знаменитой Bell Labs, только поменьше) над крупными коммерческими базами данных. Оказалось, что если найти определенные правила, некоторые запросы к этим базам можно ускорить на несколько порядков. Я заинтересовался вопросом - можно ли находить такие правила автоматически, и занялся применением идей искусственного интеллекта к большим базам данных. Побывав в 1988 году на встрече (workshop) по этой теме (в рамках конференции AAAI ’88), я понял, что этому мероприятию нужна более четкая фокусировка. По молодости лет я не представлял себе, каких усилий стоит организовать такую встречу, и поэтому в 1989 взялся за организацию воркшопа сам. Термин "датамайнинг" я считал недостаточно завлекательным (sexy) и вместо него предложил назвать тему "открытие знаний в базах данных" (Knowledge Discovery in Databases, KDD). Это название подчеркивало, что конечная цель работы - знания, и намекало на дух первооткрывательства, сопутствующий поиску знаний. Тогда же я начал новый проект в GTE Labs, и это был первый в мире проект по KDD.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Журнал «Компьютерра» № 11 от 20 марта 2007 года»
Представляем Вашему вниманию похожие книги на «Журнал «Компьютерра» № 11 от 20 марта 2007 года» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Журнал «Компьютерра» № 11 от 20 марта 2007 года» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.