William Stanek - Windows Server 2012 R2 Storage, Security, & Networking Pocket Consultant
Здесь есть возможность читать онлайн «William Stanek - Windows Server 2012 R2 Storage, Security, & Networking Pocket Consultant» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: ОС и Сети, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.
- Название:Windows Server 2012 R2 Storage, Security, & Networking Pocket Consultant
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Windows Server 2012 R2 Storage, Security, & Networking Pocket Consultant: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Windows Server 2012 R2 Storage, Security, & Networking Pocket Consultant»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Windows Server 2012 R2 Storage, Security, & Networking Pocket Consultant — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Windows Server 2012 R2 Storage, Security, & Networking Pocket Consultant», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
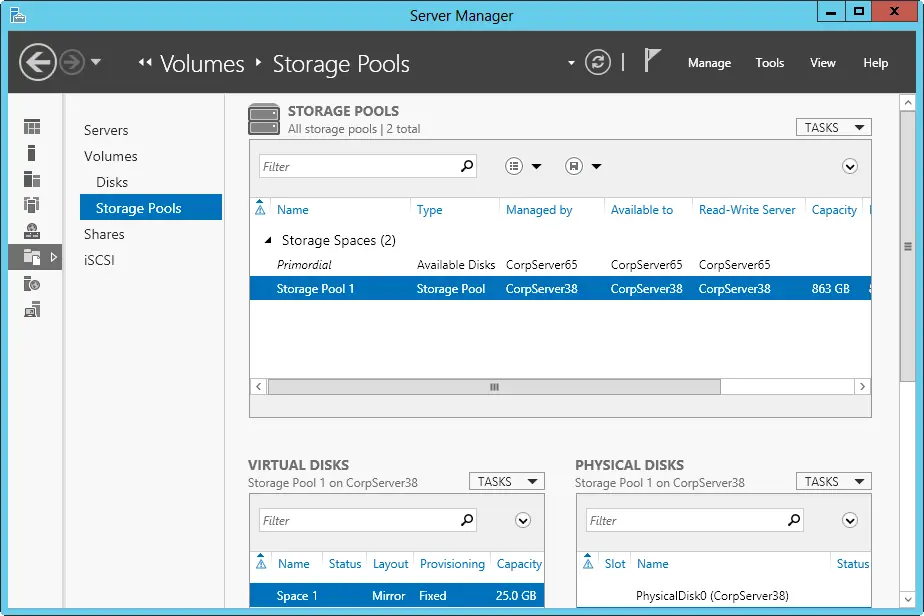
FIGURE 2–7Create and manage storage pools.
Working with storage pools is a multistep process:
1.You create storage pools to pool available space on one or more disks.
2.You allocate space from this pool to create one or more virtual disks.
3.You create one or more volumes on each virtual disk to allocate storage for file systems.
The sections that follow examine procedures related to each of these steps.
Creating a storage pool
Storage pools allow you to pool available space on disks so that units of storage (virtual disks) can be allocated from this pool. To create a storage pool, you must have at least one unused disk and a storage subsystem to manage it. This storage subsystem can be the one included with the Storage Spaces feature or a subsystem associated with attached storage.
When a computer has extra hard drives in addition to the hard drive on which Windows is installed, you can allocate one or more of the additional drives to a storage pool. However, keep in mind that if you use a formatted drive with a storage pool, Windows permanently deletes all the files on that drive. Additionally, it’s important to point out that physical disks with the MBR partition style are converted automatically to the GPT partition style when you add them to a storage pool and create volumes on them.
Each physical disk allocated to the pool can be handled in one of three ways:
■As a data store that is available for use
■As a data store that can be manually allocated for use
■As a hot spare in case a disk in the pool fails or is removed from the subsystem
Types of volumes you can create are as follows:
■ Simple VolumesCreates a simple volume by writing one copy of your data to one or more drives. With simple volumes, there is no redundancy and no associated overhead. As an example, you can create a single volume that spans two 2-TB drives, making 4 TB of storage available. However, because there is no resiliency, a failure of any drive in a simple volume causes the entire volume to fail.
■ Two-way mirrorsCreates a mirrored set by writing two copies of a computer’s data, helping to protect against a single drive failure. Two-way mirrors require at least two drives. With two-way mirrors, there is a 1/2 (50 percent) overhead for redundancy with two drives. As an example, you could allocate two 2-TB drives as a two-way mirror, giving you 2 TB of mirrored storage.
■ Parity volumesCreates a volume that uses disk striping with parity, helping to provide fault tolerance with less overhead than mirroring. Parity volumes require at least three drives. With parity volumes there is a 1/3 (33.33 percent) overhead for redundancy with three drives. As an example, you could allocate three 2-TB drives as a parity volume, giving you 4 TB of protected storage.
■ Dual parity volumesCreates a volume that uses disk striping with two sets of parity data, helping to protect against two simultaneous drive failures while requiring less overhead than three-way mirroring. Dual parity volumes require at least seven drives.
■ Three-way mirrorsCreates a mirrored set by writing three copies of a computer’s data and by using disk striping with mirroring, helping to protect against two simultaneous drive failures. Although three-way mirrors do not have a penalty for read operations, they do have a performance penalty for write operations because of the overhead associated with having to write data to three separate disks. This overhead can be mitigated by using multiple drive controllers. Ideally, you’ll want to ensure that at least three drive controllers are used. Three-way mirrors require at least five drives.
If you are familiar with RAID 6, you are familiar with dual parity volumes. Although dual parity does not have a penalty for read operations, it does have a performance penalty for write operations because of the overhead associated with calculating and writing dual parity values. With standard dual parity volumes, the usable capacity of dual parity volumes is calculated as the sum of the number of volumes minus two times the size of the smallest volume in the array or (N -2) X MinimumVolumeSize. For example, with 7 volumes and the smallest volume size of 1 TB, the usable capacity typically is 5 TB [calculated as (7–2) * 1 TB = 5 TB].
Although logically it would seem that you need at least six drives to have three mirrored copies of data, mathematically you need only five. Why? If you want three copies of your data, you need at least 15 logical units of storage to create those three copies. Divide 15 by 3 to come up with the number of disks required, and the answer is that you need 5 disks. Thus, Storage Spaces uses 1/3 of each disk to store original data and 2/3 of each disk to store copies of data. Following this, a three-way mirror with five volumes has a 2/3 (66.66 percent) overhead for redundancy. Or put another way, you could allocate five 3-TB drives as a three-way mirror, giving you 5 TB of mirrored storage (and 10 TB of overhead).
With single parity volumes, data is written out horizontally with parity calculated for each row of data. Dual parity differs from single parity in that row data is not only stored horizontally, it is also stored diagonally. If a single disk fails or a read error from a bad bit or block error occurs, the data is re-created by using only the horizontal row parity data (just as in single parity volumes). In the case of a multiple drive issue, the horizontal and diagonal row data are used for recovery.
To understand how dual parity typically works, consider the following simplified example. Each horizontal row of data has a parity value, the sum of which is stored on the parity disk for that row (and calculated by using an exclusive OR). Each horizontal parity stripe misses one and only one disk. If the parity value is 2, 3, 1, and 4 on disks 0, 1, 2, and 3 respectively, the parity sum stored on the disk 4 (the parity disk for this row) is 10 (2 + 3 + 1 + 4 = 10). If disk 0 were to have a problem, the parity value for the row on this disk could be restored by subtracting the remaining horizontal values from the horizontal parity sum (10 — 3–1 — 4 = 2).
The second set of parity data is written diagonally (meaning in different data rows on different disks). Each diagonal row of data has a diagonal parity value, the sum of which is stored on the diagonal parity disk for that row (and calculated by using an exclusive OR). Each diagonal parity stripe misses two disks: one disk in which the diagonal parity sum is stored and one disk that is omitted from the diagonal parity striping. Additionally, the diagonal parity sum includes a data row from the horizontal row parity as part of its diagonal parity sum.
If the diagonal parity value is 1, 4, 3, and 7 on disks 1, 2, 3, and 4 respectively (with four associated horizontal rows), the diagonal parity sum stored on disk 5 (the diagonal parity disk for this row) is 15 (4 + 1 + 3 + 7 = 15) and the omitted disk is disk 0. If disk 2 and disk 4 were to have a problem, the diagonal parity value for the row can be used to restore both of the lost values. The missing diagonal value is restored first by subtracting the remaining diagonal values from the diagonal parity sum. The missing horizontal value is restored next by subtracting the remaining horizontal values for the subject row from the horizontal parity sum for that row.
NOTE Keep in mind that dual parity, as implemented in Storage Spaces, uses seven disks, and the previous example was simplified. Although parity striping with seven disks works differently than as discussed in this example, the basic approach uses horizontal and vertical stripes.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Windows Server 2012 R2 Storage, Security, & Networking Pocket Consultant»
Представляем Вашему вниманию похожие книги на «Windows Server 2012 R2 Storage, Security, & Networking Pocket Consultant» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.







Обсуждение, отзывы о книге «Windows Server 2012 R2 Storage, Security, & Networking Pocket Consultant» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.