Роберт Лав - Разработка ядра Linux
Здесь есть возможность читать онлайн «Роберт Лав - Разработка ядра Linux» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2006, ISBN: 2006, Издательство: Издательский дом Вильямс, Жанр: ОС и Сети, Программирование, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Разработка ядра Linux
- Автор:
- Издательство:Издательский дом Вильямс
- Жанр:
- Год:2006
- Город:Москва
- ISBN:5-8459-1085-4
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Разработка ядра Linux: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Разработка ядра Linux»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Книга может быть рекомендована как начинающим, так и опытным разработчикам программного обеспечения, а также в качестве дополнительных учебных материалов.
Разработка ядра Linux — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Разработка ядра Linux», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:

Рис. A.1. Односвязный список
В. некоторых связанных списках содержится указатель не только на следующий, но и на предыдущий элемент ( prev). Эти списки называются двухсвязными ( doubly linked ), потому что они связаны как вперед, так и назад. Связанные списки, аналогичные тем, что показаны на рис. А.1, называются односвязными ( singly linked ). Двухсвязный список показан на рис. А.2.

Рис. А.2. Двухсвязный список
Кольцевые связанные списки
Последний элемент связанного списка не имеет следующего за ним элемента, и значение указателя nextпоследнего элемента обычно устанавливается равным специальному значению, обычно NULL, чтобы показать, что этот элемент списка является последним. в определенных случаях последний элемент списка не указывает на специальное значение, а указывает на первый элемент этого же списка. Такой список называется кольцевым связанным списком ( circular linked list ), поскольку связи образуют топологию кольца. Кольцевые связанные списки могут быть как односвязными, так и двухсвязными. В двухсвязных кольцевых списках указатель prev первого элемента указывает на последний элемент списка. На рис. А.3 и А.4 показаны соответственно односвязные и двухсвязные кольцевые списки.
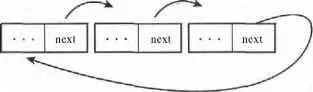
Рис. A.3. Односвязный кольцевой список
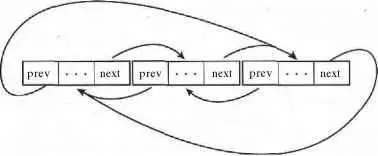
Рис. А.4. Двухсвязный кольцевой список
Стандартной реализацией связанных списков в ядре Linux является двухсвязный кольцевой список . Такие связанные списки обеспечивают наибольшую гибкость работы.
Перемещение по связанному списку
Перемещение по связанному списку выполняется последовательно (линейно). После того как просмотрен текущий элемент, выполнятся разыменование его указателя next, что позволяет обратиться к следующему за ним элементу и т.д. Это самый простой и наиболее подходящий метод перемещения но связанному списку. Если важна возможность произвольного доступа к любому элементу контейнера, то связанные списки не используются. Связанные списки используются, когда важна возможность динамического добавления и удаления элементов, а также возможность последовательного прохождения по всем элементам списка.
Часто первый элемент списка представлен с помощью специального указателя, который называется головным элементом или головой (head), что дает возможность быстро и легко обращаться к первому элементу. В некольцевом связанном списке последний элемент отличается тем, что его указатель равен значению NULL. В кольцевом связанном списке последний элемент отличается тем, что указывает на головной элемент. Таким образом прохождение списка можно выполнить линейно, начиная с первого элемента и заканчивая последним. В двухсвязном списке прохождение можно также выполнить и в противоположном направлении, начиная с последнего и заканчивая первым элементом. Конечно, если задан определенный элемент списка, то можно перейти по списку вперед и назад на заданное количество элементов. При этом нет необходимости проходить весь список.
Реализация связанных списков в ядре Linux
В ядре Linux для прохождения по связанным спискам используется унифицированный подход. При прохождении связанного списка, если не важен порядок прохода, эту операцию не обязательно начинать с головного элемента, на самом деле вообще не важно, с какого элемента списка начинать прохождение! Важно только, чтобы при таком прохождении были пройдены все узлы. В большинстве случаев нет необходимости вводить концепции первого и последнего элементов. Если в кольцевом связанном списке содержится коллекция несортированных данных, то любой элемент можно назвать головным. Для прохождения всего связанного списка необходимо взять любой элемент и следовать за указателями, пока снова не вернемся к тому элементу, с которого начали обход списка. Это избавляет от необходимости вводить специальный головной элемент. Кроме того, упрощаются процедуры работы со связанными списками. Каждая подпрограмма должна просто принимать указатель на один элемент — любой элемент списка. Разработчики ядра даже немножко гордятся такой остроумной реализацией.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Разработка ядра Linux»
Представляем Вашему вниманию похожие книги на «Разработка ядра Linux» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.









Обсуждение, отзывы о книге «Разработка ядра Linux» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.