Роберт Лав - Разработка ядра Linux
Здесь есть возможность читать онлайн «Роберт Лав - Разработка ядра Linux» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2006, ISBN: 2006, Издательство: Издательский дом Вильямс, Жанр: ОС и Сети, Программирование, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Разработка ядра Linux
- Автор:
- Издательство:Издательский дом Вильямс
- Жанр:
- Год:2006
- Город:Москва
- ISBN:5-8459-1085-4
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Разработка ядра Linux: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Разработка ядра Linux»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Книга может быть рекомендована как начинающим, так и опытным разработчикам программного обеспечения, а также в качестве дополнительных учебных материалов.
Разработка ядра Linux — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Разработка ядра Linux», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Порядок следования байтов
Порядок следования байтов ( byte ordering ) — это порядок, согласно которому байты расположены в машинном слове. Для разных процессоров может использоваться один из двух типов нумерации байтов в машинном слове: наименее значимый (самый младший) байт является либо самым первым (самым левым, left-most), либо самым последним (самым правым, right-most) в слове. Порядок байтов называется обратным ( big-endian ), если наиболее значимый (самый старший) байт хранится первым, а за ним идут байты в порядке убывания значимости. Порядок байтов называется прямым ( little-endian ), если наименее значимый (самый младший) байт хранится первым, а за ним следуют байты в порядке возрастания значимости.
Даже не пытайтесь основываться на каких-либо предположениях о порядке следования байтов при написании кода ядра (конечно, если код не предназначен для какой-либо конкретной аппаратной платформы). Операционная система Linux поддерживает аппаратные платформы с обоими порядками байтов, включая и те машины, на которых используемый порядок байтов можно сконфигурировать на этапе загрузки системы, а общий код должен быть совместим с любым порядком байтов.
На рис. 19.1 показан пример обратного порядка следования байтов, а на рис. 19.2 — прямого порядка следования байтов.
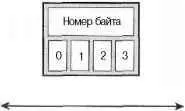
Рис. 19.1. Обратный (big-endian) порядок следования байтов
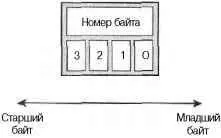
Рис. 19.2. Прямей (little-endian) порядок следования байтов
Аппаратная платформа i386 использует прямой (little-endian) порядок байтов. Большинство других аппаратных платформ обычно использует обратный (big-endian) порядок.
Рассмотрим, что эти типы кодирования обозначают на практике и как выглядит двоичное представление числа 1027, которое хранится в виде четырехбайтового целочисленного типа данных.
00000000 00000000 00000100 00000011
Внутренние представления этого числа в памяти при использовании прямого и обратного порядка байтов отличаются, как это показано в табл. 19.3.
Таблица 19.3. Расположение данных в памяти для разных порядков следования байтов
| Адрес | Обратный порядок | Прямой порядок |
|---|---|---|
| 0 | 00000000 | 00000011 |
| 1 | 00000000 | 00000100 |
| 2 | 00000100 | 00000000 |
| 3 | 00000011 | 00000000 |
Обратите внимание на то, что для аппаратной платформы с обратным порядком байтов самый старший байт записывается в самый минимальный адрес памяти.
И наконец, еще один пример — фрагмент кода, который позволяет определить порядок байтов для той аппаратной платформы, на которой он выполняется.
int x = 1;
if (*(char*)&x == 1)
/* прямой порядок */
else
/* обратный порядок */
Этот пример работает как в ядре, так и в пространстве пользователя.
История терминов big-endian и little-endian
Термины big-endian и little-endian заимствованы из сатирического романа Джонатана Свифта "Путешествие Гулливера", который был издан в 1726 году. В этом романс наиболее важной политической проблемой народа лилипутов была проблема, с какого конца следует разбивать яйцо: с тупого (big) или острого (little). Тех, кто предпочитал тупой конец называли "тупоконечниками" (big-endian), тех же, кто предпочитал острый конец, называли "остроконечниками" (little-endian).
Аналогия между дебатами лилипутов и спорами о том, какой порядок байтов лучше, говорит о том, что это вопрос больше политический, чем технический.
Порядок байтов в ядре
Для каждой аппаратной платформы, которая поддерживается ядром Linux, в файле определена одна из двух констант __BIG_ENDIANили __LITTLE_ENDIAN, в соответствии с используемым порядком байтов.
В этот заголовочный файл также включаются макросы из каталога include/linux/byteorder/, которые помогают конвертировать один порядок байтов в другой. Ниже показаны наиболее часто используемые макросы.
u32 __cpu_to_be32(u32); /* преобразовать порядок байтов текущего
процессора в порядок big-endian */
u32 __cpu_to_le32(u32); /* преобразовать порядок байтов текущего
процессора в порядок little-endian */
u32 __be32_to_cpu(u32); /* преобразовать порядок байтов big-endian в
порядок байтов текущего процессора */
u32 __lе32_to_cpu(u32); /* преобразовать порядок байтов little-endian
в порядок байтов текущего процессора */
Интервал:
Закладка:
Похожие книги на «Разработка ядра Linux»
Представляем Вашему вниманию похожие книги на «Разработка ядра Linux» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.









Обсуждение, отзывы о книге «Разработка ядра Linux» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.