Брайан Керниган - UNIX — универсальная среда программирования
Здесь есть возможность читать онлайн «Брайан Керниган - UNIX — универсальная среда программирования» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 1992, ISBN: 1992, Издательство: Финансы и статистика, Жанр: ОС и Сети, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:UNIX — универсальная среда программирования
- Автор:
- Издательство:Финансы и статистика
- Жанр:
- Год:1992
- Город:Москва
- ISBN:5-289-00253-4
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
UNIX — универсальная среда программирования: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «UNIX — универсальная среда программирования»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
.
Для программистов-пользователей операционной системы UNIX.
UNIX — универсальная среда программирования — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «UNIX — универсальная среда программирования», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Генератор yaccсам по себе представляется мощным программным средством. Его изучение потребует от вас, конечно, некоторых усилий, но все ваши "затраты" многократно окупятся. Анализаторы, создаваемые yacc, — небольшие, эффективные и корректные (хотя за семантические преобразования отвечаете вы). Кроме того, многие неприятные проблемы, связанные с процессом разбора, решаются автоматически. Программы языковых распознавателей достаточно легко создавать и, что, возможно, еще более важно, изменять по мере совершенствования определения языка.
Исходный текст hoc1состоит из грамматических правил с описанием действий лексической процедуры yylexи функции main, хранимых в одном файле hoc.y. (Имена файлов, содержащих текст для yacc, традиционно оканчиваются на .y, но это соглашение в отличие от соглашения о сси .c не поддерживает сам yacc.) Грамматика составляет первую половину файла hoc.y:
$ cat hoc.y
%{
#define YYSTYPE double /* data type of yacc stack */
%}
%token NUMBER
%left '+' /* left associative, same precedence */
%left '*' '/' /* left assoc., higher precedence */
%%
list: /* nothing */
| list '\n'
| list expr '\n' { printf("\t%.8g\n", $2); }
;
expr: NUMBER { $$ = $1; }
| expr '+' expr { $$ = $1 + $3; }
| expr '-' expr { $$ = $1 - $3; }
| expr '*' expr { $$ = $1 * $3; }
| expr '/' expr { $$ = $1 / $3; }
| '(' expr ')' { $$ = $2; }
;
%%
/* end of grammar */
...
Вы видите, как много информации заключено в этих нескольких строках. Поскольку мы не можем вам здесь все объяснить, в частности, как работает синтаксический анализатор, обратитесь к справочному руководству по yacc.
Альтернативные правила разделены символом '|'. С каждым грамматическим правилом может быть связано определенное действие, которое выполняется, когда экземпляр этого правила распознается во входном потоке. Действие описывается последовательностью операторов Си, заключенной в фигурные скобки. Внутри последовательности $n(т.е. $1, $2и т.д.) определяет значение, вырабатываемое n-м компонентом правила, а $$значение, вырабатываемое всеми компонентами правила в целом. Так, в правиле
expr: NUMBER { $$ = $1; }
$1— значение, вырабатываемое при распознавании NUMBER, и оно же является результирующим значением expr. В данном случае присваивание $$ = $1может быть опущено, так как $$всегда принимает значение $1(если не устанавливается явно каким либо иным образом). В следующей строке с правилом
expr: expr '+' expr { $$ = $1 + $3; }
результирующее значение exprявляется суммой двух компонентов, тоже expr. Отметим, что $2соответствует '+'т.е. каждый компонент пронумерован.
Строкой выше выражение, за которым следует символ перевода строки ( '\n'), распознается как список , и печатается его значение. Если за такой конструкцией следует конец входного потока, процесс разбора завершается правильно. Список может быть пустой строкой; так учитываются пустые входные строки.
Формат входного потока для yacc— произвольный. Наш формат рекомендуется как стандартный.
В этой реализации процесс распознавания или разбора входного потока приводит к немедленному вычислению выражения. В более сложных решениях (включая hoc4и его последующие версии) процесс разбора порождает код для дальнейшего выполнения.
Наглядно представить разбор вам поможет рис. 8.1, где изображено дерево разбора. Кроме того, вы должны знать, как вычисляются значения и как они распространяются от листьев к корню дерева.
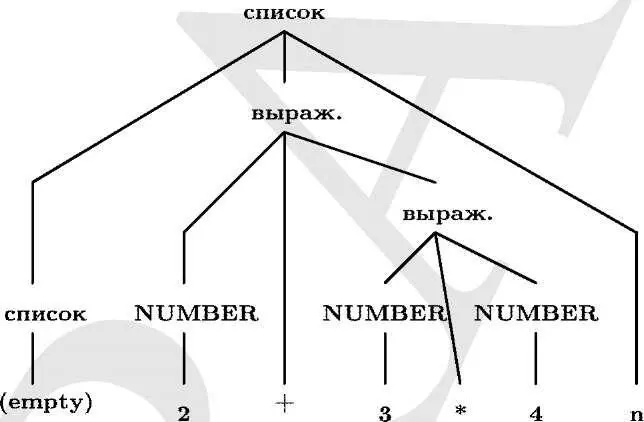
Рис. 8.1 : Дерево разбора для 2 + 3*4
Реально значения не полностью разобранных правил хранятся в стеке и через стек передаются от одного правила к следующему. Обычно данные в стеке имеют целый тип, но поскольку мы в своей работе используем числа с плавающей точкой, необходимо переопределить значение по умолчанию. Определение
#define YYSTYPE double
устанавливает двойную точность для типа данных стека.
Теперь перейдем к описанию синтаксических классов, распознаваемых лексическим анализатором, если только они не являются литералами, состоящими из одного символа вида '+'и '-'. Описание %tokenспецифицирует одни или несколько таких объектов. При необходимости можно задать левую или правую ассоциативность, используя %leftили %rightвместо %token.
Интервал:
Закладка:
Похожие книги на «UNIX — универсальная среда программирования»
Представляем Вашему вниманию похожие книги на «UNIX — универсальная среда программирования» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.






![Александр Мещеряков - Terra Nipponica [Среда обитания и среда воображения]](/books/393699/aleksandr-mecheryakov-terra-nipponica-sreda-obitani-thumb.webp)


Обсуждение, отзывы о книге «UNIX — универсальная среда программирования» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.