Жан-Батист Мишель - Неизведанная территория. Как «большие данные» помогают раскрывать тайны прошлого и предсказывать будущее нашей культуры
Здесь есть возможность читать онлайн «Жан-Батист Мишель - Неизведанная территория. Как «большие данные» помогают раскрывать тайны прошлого и предсказывать будущее нашей культуры» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2016, ISBN: 2016, Издательство: АСТ, Жанр: Базы данных, foreign_comp, foreign_edu, Прочая научная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Неизведанная территория. Как «большие данные» помогают раскрывать тайны прошлого и предсказывать будущее нашей культуры
- Автор:
- Издательство:АСТ
- Жанр:
- Год:2016
- Город:Москва
- ISBN:978-5-17-088935-8
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Неизведанная территория. Как «большие данные» помогают раскрывать тайны прошлого и предсказывать будущее нашей культуры: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Неизведанная территория. Как «большие данные» помогают раскрывать тайны прошлого и предсказывать будущее нашей культуры»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Неизведанная территория. Как «большие данные» помогают раскрывать тайны прошлого и предсказывать будущее нашей культуры — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Неизведанная территория. Как «большие данные» помогают раскрывать тайны прошлого и предсказывать будущее нашей культуры», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Наш ципфовский список слов представляет собой вполне удобный информационный источник. Если какого-то слова в нем нет, то значит, оно встречается еще реже, чем наименее часто встречающиеся слова в словаре, – соответственно, у нас есть основания считать, что это вообще не слово. Если же оно появляется, то это значит, что оно вполне достойно включения в словарь (а если его там нет, то это может вызвать вполне законное недоумение).
Именно в этом вся прелесть обладания объективным словарем. Все эти годы во время учебы или при игре в «Эрудит» мы использовали для проверки словари. Теперь же, получив независимый способ оценки словарного состава, мы приобрели возможность оценить точность словаря и создавших его лексикографов. Кабинетные лексикографы занимались своим делом на протяжении столетий, но только после появления n -грамов стало возможным появление кабинетных лексикограферологов («лексикограферология» – труд безобидных работяг; «лексикограферолог» – еще более безобидный работяга).
Затем мы задали самый фундаментальный вопрос в области лексикограферологии – какая доля нашего ципфовского списка слов представлена в имеющихся словарях?
Она оказалась на удивление малой. Oxford English Dictionary , самый крупный словарь английского языка, содержит менее 500 тысяч слов. Его лексикон составляет примерно треть нашего списка. Объем всех остальных словарей еще меньше.
Как такое может быть? Неужели лексикографы действительно настолько плохо разбираются в том, что происходит в их собственном языке?
Лексическая темная материя
Мы немного поспешили с выводами. Большинство словарей не претендует на то, чтобы включить все слова, имеющиеся в языке. По сути, составители многих словарей даже стараются исключать те или иные слова, пусть даже часто использующиеся в языке, например [105]:
1. Слова, состоящие не только из букв (например, 3.14 и l8r ).
2. Составные слова ( whalewatching – «наблюдение за китами»).
3. Нестандартная орфография ( untill вместо until – «до тех пор, пока»).
4. Слова, которым сложно дать однозначное описание ( AAAAAAARGH ).
Поэтому с нашей стороны было бы несправедливым тыкать пальцем в людей, которые даже не пытались включать в словарь определенные типы слов. Чтобы убедиться в том, что составители словарей исключают из них именно то, что планировали, мы рассчитали, какая часть нашего списка слов пришла из указанных выше четырех категорий.
Это сократило наш список с 1,5 миллиона до немногим более миллиона слов. Но все равно наш ципфовский лексикон почти в два раза превышал по объему количество статей в Oxford English Dictionary . Иными словами, даже самый полный словарь английского языка упускает большинство слов. Эти задокументированные слова включали в себя множество ярких понятий, таких как aridification (процесс, в результате которого географический регион становится засушливым), slenthem (музыкальный инструмент) и, что показалось вполне уместным, слово deletable («допускающий удаление»).
Так в чем же состоит проблема словарей?
Ответ – частотность употребления. Судя по всему, составители словарей проводят отличную работу по отбору самых частых слов. В этом смысле словари совершенно идеальны: они действительно содержат буквально 100% всех слов – если только эти слова встречаются чаще, чем один раз на миллион, например слово dynamite («динамит»). Если слово появляется хотя бы один раз в случайной стопке из десяти книг, словарь зафиксирует его и даст ему определение.
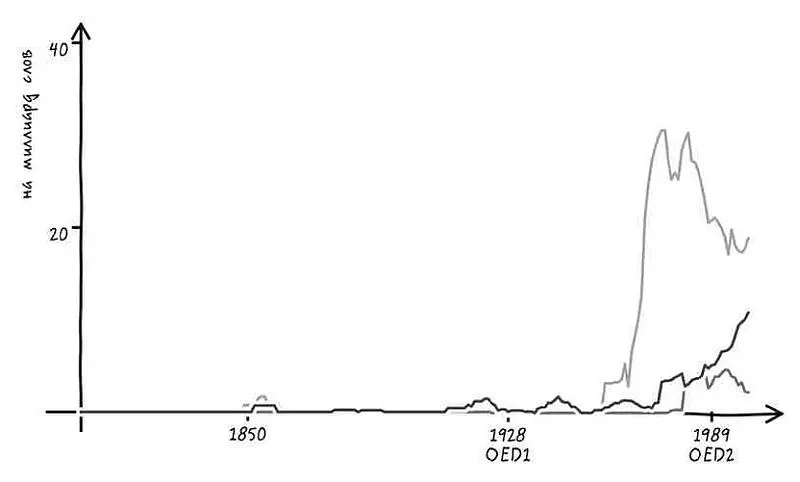
Однако у лексикографов возникает немалая проблема с редкими словами. Как только частота слова оказывается меньше, чем одно на миллион, шансы на то, что оно не будет включено в словарь, резко возрастают. Если посмотреть на слова с частотой употребления немногим меньшей, чем одно на миллиард, в словари будет включена лишь четверть.
Стоит помнить о правиле, установленном Ципфом, – большинство слов встречается достаточно редко. Соответственно, если словари упускают из вида большинство редких слов, то можно сказать, что они упускают большинство слов как таковых.
В результате оказывается, что 52% английского языка – большинство слов, используемых в книгах, – представляют собой лексическую темную материю. Подобно темной материи в космосе, составляющей основной объем Вселенной, лексическая темная материя составляет основную массу нашего языка, которая не может быть протестирована обычными способами [106].
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Неизведанная территория. Как «большие данные» помогают раскрывать тайны прошлого и предсказывать будущее нашей культуры»
Представляем Вашему вниманию похожие книги на «Неизведанная территория. Как «большие данные» помогают раскрывать тайны прошлого и предсказывать будущее нашей культуры» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.









Обсуждение, отзывы о книге «Неизведанная территория. Как «большие данные» помогают раскрывать тайны прошлого и предсказывать будущее нашей культуры» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.