Жан-Батист Мишель - Неизведанная территория. Как «большие данные» помогают раскрывать тайны прошлого и предсказывать будущее нашей культуры
Здесь есть возможность читать онлайн «Жан-Батист Мишель - Неизведанная территория. Как «большие данные» помогают раскрывать тайны прошлого и предсказывать будущее нашей культуры» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2016, ISBN: 2016, Издательство: АСТ, Жанр: Базы данных, foreign_comp, foreign_edu, Прочая научная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Неизведанная территория. Как «большие данные» помогают раскрывать тайны прошлого и предсказывать будущее нашей культуры
- Автор:
- Издательство:АСТ
- Жанр:
- Год:2016
- Город:Москва
- ISBN:978-5-17-088935-8
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Неизведанная территория. Как «большие данные» помогают раскрывать тайны прошлого и предсказывать будущее нашей культуры: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Неизведанная территория. Как «большие данные» помогают раскрывать тайны прошлого и предсказывать будущее нашей культуры»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Неизведанная территория. Как «большие данные» помогают раскрывать тайны прошлого и предсказывать будущее нашей культуры — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Неизведанная территория. Как «большие данные» помогают раскрывать тайны прошлого и предсказывать будущее нашей культуры», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Обратите внимание, что Ципф намного опередил свое время в понимании того, что только начинают понимать ученые наших дней, – как логически анализировать информацию. Ципф умело переформулировал важные для себя вопросы в свете доступных ему данных. Вместо того чтобы заняться неразрешимой проблемой подсчета всех слов, он сфокусировался на вполне решаемой проблеме подсчета слов в книге «Улисс». И если бы он был жив в наши дни, то оказался бы у дверей Google в тот же самый момент, когда компания объявила о своем проекте по оцифровке книг.
Вооружившись индексом Хенли, Ципф проранжировал слова в « Улиссе » по частоте употребления [51]. Первое место занял определенный артикль the , использованный 14 877 раз – то есть он представлял собой каждое восемнадцатое слово. Десятым по частоте оказалось слово I («я») с 2653 случаями употреблений. Слово say , встречавшееся в книге 265 раз, оказалось на сотой позиции. Слово s tep с 26 случаями употреблений заняло в рейтинге Ципфа тысячное место. А чтобы оказаться на десятитысячной позиции, слову indisputable («бесспорный») было достаточно появиться в тексте всего два раза.
Изучая получившийся список, Ципф заметил кое-что любопытное – а именно обратную связь между позицией слова и частотой его использования. Если номер позиции слова был в 10 раз выше – пятисотое место вместо пятидесятого, – то оно встречалось в 10 раз реже. Таким образом his («его»), оказавшееся на восьмом месте с 3326 упоминаниями, встречается в 10 раз чаще, чем слово eyes («глаза») (восьмидесятая позиция, 330 случаев употреблений). Иными словами, можно было сказать, что редких слов гораздо больше, чем можно было ожидать. В «Улиссе » лишь 100 слов используется более 2653 раз. Однако в книге есть сто слов, использующихся более 265 раз, тысяча слов, использующихся более 26 раз, и так далее.
Кроме того, как вскоре обнаружил Ципф, это было характерно не только для слов в « Улиссе » Джойса. Такая же закономерность проявлялась в словах из газет, текстов, написанных на китайском языке и латыни, и практически во всех остальных информационных источниках, к которым он обращался. Это открытие, называемое в наши дни законом Ципфа, оказалось универсальным организующим принципом для всех известных языков [52].
Мир глазами Ципфа
До Ципфа ученые полагали, что большинство вещей, поддающихся измерению, ведут себя подобно человеческому росту.
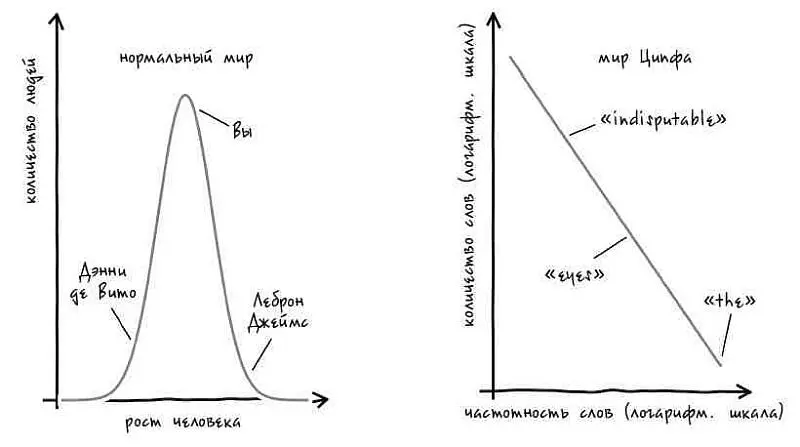
Рост человека не очень сильно варьируется. Рост 90% жителей США составляет от 155 см до 185 см. Разумеется, рост некоторых особенно высоких баскетболистов достигает 220 см и выше, а рост самого низкого взрослого человека в мире составляет менее 62 см. Однако подобные случаи встречаются крайне редко. Но даже с учетом этих крайностей самые высокие люди всего в 4–5 раз выше самых низкорослых [53]. У математиков имеется особый термин для описания распределения такого рода, при котором значения настолько тесно группируются вокруг среднего значения. Подобное часто встречающееся распределение называется «нормальным». До Ципфа люди считали, что мы живем в нормальном мире, где нормальным оказывалось бы все окружающее.
Однако, как мы уже видели, мир слов далек от нормального – распределение в нем соответствует вполне определенному, но кажущемуся на первый взгляд странным математическому принципу. В наши дни ученые называют такое поведение степенными законами [54]. Удивительно, но как только Ципф обнаружил свой первый степенной закон в языке, то начал тут же находить и другие его проявления.
Например, Ципф обнаружил, что степенным законам следуют показатели богатства и доходов. Если бы ваш рост был пропорционален величине вашего банковского счета, а среднее американское домохозяйство имело рост около 170 см, то рост Билла Гейтса оказался бы больше, чем расстояние от Земли до Луны [55]. Величина статей в Encyclopedia Britannica также следует степенному закону, как и тираж газет. Ученые, следовавшие по стопам Ципфа, обнаружили тысячи других примеров: размер городов, частотность определенных фамилий, количество жертв в ходе военных действий, продолжительность аплодисментов после спектакля, популярность людей в Facebook и Twitter , объем пищи, потребляемой животными, трафик на веб-сайтах, доля белков в наших клетках, количество клеток различных типов в наших телах, распространенность тех или иных биологических видов в наших экосистемах и даже размер дырок в швейцарском сыре. Степенному закону следует даже продолжительность отключений электричества (хотя в данном случае, возможно, нам стоит назвать это «законом отсутствия энергии»).
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Неизведанная территория. Как «большие данные» помогают раскрывать тайны прошлого и предсказывать будущее нашей культуры»
Представляем Вашему вниманию похожие книги на «Неизведанная территория. Как «большие данные» помогают раскрывать тайны прошлого и предсказывать будущее нашей культуры» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.









Обсуждение, отзывы о книге «Неизведанная территория. Как «большие данные» помогают раскрывать тайны прошлого и предсказывать будущее нашей культуры» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.