Олег Деревенец - Песни о Паскале
Здесь есть возможность читать онлайн «Олег Деревенец - Песни о Паскале» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: Базы данных, tbg_computers, network_literature, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Песни о Паскале
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Песни о Паскале: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Песни о Паскале»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Песни о Паскале — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Песни о Паскале», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:

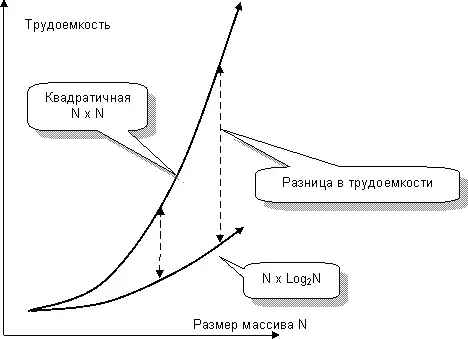
Итак, с чемпионом все ясно (рис. 96), но в чем секрет его успеха? Сравним чемпиона с отставшими. Чем больше массив, тем дольше он сортируется, – это справедливо для любого алгоритма. Долгие методы обрабатывают весь массив N раз, где N – размер массива. Поэтому их трудоемкость пропорциональна произведению N•N. По этой формуле вычисляют площадь квадрата, и такую зависимость называют квадратичной.
Иное дело – чемпион. Дробя массив на мелкие участки, быстрый алгоритм уменьшает число прохождений всего массива до величины Log 2N. Поэтому его трудоемкость растёт пропорционально произведению N•Log 2N. Опять логарифм? Да, мы помним его по двоичному поиску. Поскольку логарифм числа растёт очень медленно, это объясняет чемпионство QuickSort (рис. 97).
• Двоичный поиск – это самый быстрый способ поиска, но он требует предварительной сортировки массива.
• Простые методы сортировки – BubbleSort и FarmSort – работают очень медленно, съедая всю экономию от двоичного поиска.
• QuickSort – это быстрый способ сортировки, который в сочетании с резвым двоичным поиском ускорит работу ваших программ.
А) Исследуйте процедуру быстрой сортировки в пошаговом режиме (задайте небольшой размер сортируемого массива). Обратите внимание на изменение границ сортируемой части.
Б) Определите количество повторных входов в процедуру QuickSort и выходов из нее. Объявите глобальную переменную, назовем её Level – «уровень». В главной программе, перед вызовом процедуры QuickSort, эту переменную надо обнулить, а внутри процедуры добавить следующие операторы.
В начале процедуры QuickSort:
begin
Inc(Level); Writeln('Уровень на входе = ', Level);
В конце процедуры QuickSort:
Dec(Level); Writeln('Уровень на выходе = ', Level);
end;
В) Если каждый вызов QuickSort делит массив примерно пополам, то наибольшее значение переменной Level должно составить приблизительно Log 2N (у нас размер массива задан константой CSize). Проверьте эту догадку компиляцией и запуском программы для нескольких значений CSize.
Г) В одном ряду вперемежку лежат дыни и арбузы. Могут ли фермеры отсортировать их за один проход ряда так, чтобы в начале оказались все дыни, а в конце ряда – все арбузы? Напишите такую программу, обозначив арбузы единицами, а дыни – нулями.
Глава 44
Строки

Строковый тип STRING известен нам с первых глав книги, без него компьютер не общался бы с нами на «человечьем» языке. Так изучим строки получше. В современных версиях Паскаля применяют несколько строковых типов, сейчас мы рассмотрим только короткие строки, введенные ещё в Borland Pascal (в новых версиях Паскаля этот тип называется ShortString).
С первого взгляда строка похожа на массив символов. Так ли это? – проверим. Известно, что строка может вместить до 255 символов. Объявим массив из 255 символов и сравним его размер с размером строки. Напомню, что функция SizeOf возвращает размер памяти, занимаемой переменной.
var S1 : array [1..255] of CHAR; { это массив из 255 символов }
S2 : String; { это строка длиной 255 символов }
begin
Writeln (SizeOf(S1)); { печатает 255 }
Writeln (SizeOf(S2)); { печатает 256 }
Readln;
end.
Запустили программку? И что? Странно, но размер строки S2 оказался равным 256 байтам, что на единицу больше размера массива. Почему? Где прячется ещё один байтик? Ответ представлен на рис. 98.
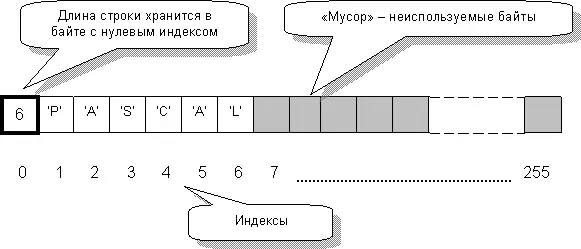
Здесь показана внутренность строковой переменной со словом «PASCAL». Байты с 1-го по 6-й содержат буквы этого слова, а остальные байты не заняты. Но в начале массива обнаружен ещё один байт – с нулевым индексом. Он содержит число 6 – это длина слова «PASCAL». Значит, строковый тип – это массив со скрытым нулевым байтом, хранящим фактическую длину строки (эту длину возвращает функция Length).
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Песни о Паскале»
Представляем Вашему вниманию похожие книги на «Песни о Паскале» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Песни о Паскале» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.