Далчи Грей - Пособие по журналистике данных
Здесь есть возможность читать онлайн «Далчи Грей - Пособие по журналистике данных» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Год выпуска: 2013, ISBN: 2013, Жанр: Справочники, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Пособие по журналистике данных
- Автор:
- Жанр:
- Год:2013
- ISBN:978-5-905600-08-1
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Пособие по журналистике данных: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Пособие по журналистике данных»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Пособие по журналистике данных — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Пособие по журналистике данных», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Данные зачастую приходят запутанными и требуют сортировки.
Данные могут включать незафиксированные элементы
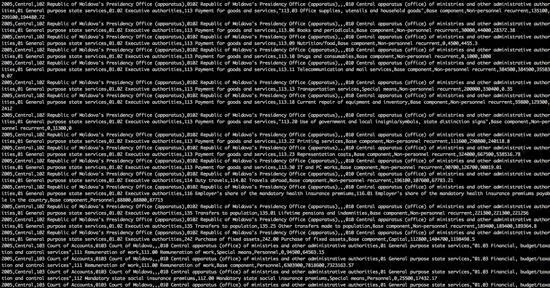
Рис 67. Messy Data
Понимайте вопросы, на которые хотите получить ответ
Во многом работа с данными напоминает интервью в прямом эфире. Вы задаете вопросы и пытаетесь выудить ответы. Но точно так же, как каждый источник может ответить только на те вопросы, в которых он сведущ, массив данных может только ответить на вопросы о том, о чем в нем имеются достоверные данные и необходимые переменные. Это означает, что вы должны как следует продумать вопросы, прежде чем собирать данные. По сути, вы работаете в обратном порядке. Сначала составьте список утверждений для вашей статьи, которые вы хотите подкрепить данными. Затем определите, какие переменные и данные необходимо собрать и проанализировать, чтобы получить такие утверждения.
Рассмотрим это на примере репортажей из местной криминальной хроники. Скажем, вы хотите написать статью о статистике преступлений, которые произошли в вашем городе. Вы хотите включить в репортаж время суток и дни недели, в которые чаще всего случаются разные виды преступлений, а также в каких частях города чаще всего случаются те или иные преступления.
Вы увидите, что запрос данных должен включать дату и время, когда о преступлении было заявлено в полицию, а также вид преступления (убийство, кража, ограбление и т.д.) и место совершения преступления. Таким образом, дата, время, вид преступления и место – минимальный набор данных, которые нужны, чтобы ответить на поставленные вопросы.
Но будьте внимательны. Есть множество потенциально интересных вопросов, ответы на которые не даст этот набор данных из четырех переменных. Это, например, раса и пол жертвы, полная стоимость украденных ценностей или кто из полицейских производит больше арестов. Вы также сможете получить данные только за определенный период (например, за последние три года), а это значит, что вы не сможете сказать, изменилась ли статистика преступлений за более долгий период времени. Эти вопросы могут выходить за планируемые рамки репортажа, и это нормально. Но будьте предусмотрительны: если вы уже начали анализировать данные, а потом решили, что хотите узнать процент преступлений, закончившихся арестом, будет уже поздно.
Хорошим советом здесь будет запросить ВСЕ переменные и данные из базы, а не только подмассив данных, который может дать информацию исключительно для текущего репортажа. На самом деле получить все данные будет дешевле, чем их часть, так как во втором случае придется платить агентству за программирование фильтра. Вы всегда сможете вычленить данные самостоятельно, а имея доступ к более широкому набору данных, сможете получить ответы, возникающие в процессе работы над статьей, и даже написать дополнительный материал. Возможно, политика конфиденциальности не позволит вам получить некоторые переменные (например, имена жертв или конфиденциальных осведомителей). Но даже часть данных это лучше, чем ничего, если вы хорошо понимаете, на какие вопросы может и не может ответить отфильтрованная база данных.
Сортировка беспорядочных данных
Самая сложная проблема в работе с базами данных заключается в том, что зачастую вам придется анализировать данные, собранные с бюрократической целью. Проблема в том, что требования, предъявляемые к точности обоих типов данных, будут различаться.
Например, база данных системы уголовного правосудия существует главным образом для того, чтобы некий подзащитный Джонс был вовремя доставлен из тюрьмы на слушание к судье Смиту. Поэтому не так уж важно, точно ли указана в базе дата рождения Джонса, правильно ли написан его домашний адрес и даже вторая инициала его имени. Эти неточные данные не помешают доставить Джонса в зал суда к судье Смиту в назначенное время.
Но такие ошибки могут помешать журналисту, работающему с данными, обнаружить в базе данных закономерность. Поэтому первым делом после получения новых данных следует определить, насколько они беспорядочны, и устранить ошибки. Сделать это быстро можно, создав таблицы частоты категориальных переменных, т.е. такие таблицы, где разброс значений по идее должен быть сравнительно небольшой. (в Excel, например, это можно сделать через фильтр или сводные таблицы).
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Пособие по журналистике данных»
Представляем Вашему вниманию похожие книги на «Пособие по журналистике данных» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Пособие по журналистике данных» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.