Далчи Грей - Пособие по журналистике данных
Здесь есть возможность читать онлайн «Далчи Грей - Пособие по журналистике данных» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Год выпуска: 2013, ISBN: 2013, Жанр: Справочники, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Пособие по журналистике данных
- Автор:
- Жанр:
- Год:2013
- ISBN:978-5-905600-08-1
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Пособие по журналистике данных: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Пособие по журналистике данных»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Пособие по журналистике данных — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Пособие по журналистике данных», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
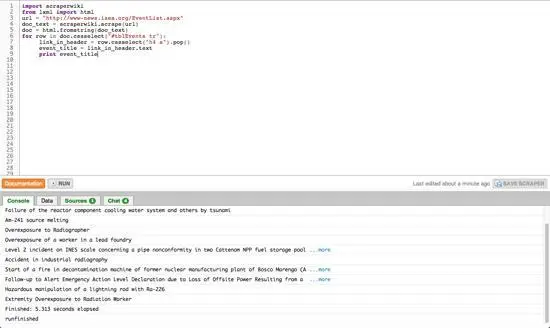
Рис 56. A scraper in action (ScraperWiki)
Вы видите работу простейшего «скребка»: он загружает веб–страницу, преобразует ее в DOM и затем предоставляет вам возможность выбирать и извлекать определенные элементы. На основе данного шаблона вы можете попробовать решить остальные вопросы, используя документацию ScraperWiki и языка Python:
Можно ли найти адрес ссылки, находящейся в заголовке каждого события?
Можно ли выбрать небольшой контейнер, который содержит дату и место, используя CSS–имя его класса, и затем извлечь текст этого элемента?
ScraperWiki предлагает небольшую базу данных для каждого «скребка», в которую вы можете сохранить ваши результаты (код), скопируйте соответствующий пример из документов ScraperWiki и адаптируйте его так, чтобы он сохранял названия, ссылки и даты событий.
Список событий включает в себя много страниц, можно ли осуществить наш поиск по всем страницам, чтобы получить информацию и о старых событиях?
Когда вы будете решать эти проблемы, изучите ScraperWiki: в имеющихся на этом ресурсе «скребках» можно найти много полезных примеров, а зачастую и довольно интересных данных. Таким образом, вам не обязательно создавать свой «скребок» с нуля: просто выберите подходящий и адаптируйте его под свои задачи.
— Фридрих Линденберг, Open Knowledge Foundation
Сеть как источник данных
Как можно узнать больше о том, что существует только в Интернете? Будь то адрес электронной почты, веб–сайт, изображение или статья в Википедии — в данной главе я расскажу вам об инструментах, которые помогут вам получить больше информации об этих элементах.
Веб–инструменты
Для начала назовем некоторые сервисы, с помощью которых можно узнать больше информации о веб–сайтах в целом.
Whois
Если вы посетите сайт
whois.domaintools.com(или просто введете whois www.example.comв приложении Terminal.app, если вы работаете на компьютере Mac), вы получите базовую регистрационную информацию практически о любом сайте. В последние годы некоторые владельцы выбирают «приватную» регистрацию, которая не позволяет просматривать их данные, однако в большинстве случаев вы увидите имя, адрес, электронную почту и номер телефона лица, зарегистрировавшего сайт. Вы также можете ввести цифровой IP–адрес и получить данные об организации или физическом лице, являющихся владельцами этого сервера. Это особенно удобно, когда вы пытаетесь получить больше информации о лицах, которые, например, нарушают условия пользования каким–либо сервисом, так как большая часть веб–сайтов регистрирует IP–адрес своих посетителей.Blekko
Поисковый движок Blekkoпредлагает необычно большой объем информации о внутренней статистике, которую он собирает в Интернете. Если вы введете доменное имя, и дополните его сочетанием «/seo», вы получите страницу с информацией об этом адресе. В первой табличке на Рис 57показано, какие другие сайты ссылаются на данный домен (в порядке популярности). Это может оказаться полезным, когда вы хотите понять, какое освещение получает сайт, и если вы хотите понять, почему он занимает высокие места в результатах поиска Google, так как эти результаты основываются именно на этих ведущих на сайт ссылках. Рис 59показывает, какие другие сайты размещаются на той же машине. Мошенники и спамеры нередко придают законный вид своей деятельности, создавая многочисленные сайты, которые ссылаются друг на друга. Внешне они выглядят как независимые домены и могут даже иметь разные регистрационные данные, однако зачастую они размещаются на одном и том же сервере, так как это значительно дешевле. Эта статистика позволит вам заглянуть внутрь скрытой бизнес–структуры исследуемого вами сайта.
Рис 57. The Blekko search engine (Blekko.com)

Рис 58. Understanding web popularity: who links to who? The other handy tab is »Crawl stats», especially the »Cohosted with» section. (Blekko.com)
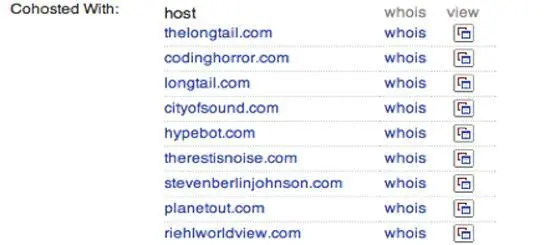
Рис 59. Spotting web spammers and scammers (Blekko.com)
Compete.com
Ресурс Compete.comзанимающийся опросом мнений американских потребителей, составляет подробную статистику использования большого количества сайтов, и некоторые из основных данных предоставляются бесплатно. Выберите вкладку «Site Profile» и введите доменное имя ( Рис 60). В результате вы увидите график трафика сайта за последний год, данные о количестве посетителей и частоте посещений (см. Рис 61). Так как в основе получаемых данных лежат опросы, эти данные являются приблизительными, однако, когда у меня появлялась возможность сравнить их с внутренними аналитическими данными, я понимал, что они являются довольно точными. В частности, их можно принимать во внимание при сравнении между собой двух сайтов, т. к., несмотря на отсутствие абсолютных цифр для этих сайтов, они хорошо показывают относительную разницу в их популярности. Данный ресурс исследует только американских потребителей, поэтому данные по большей части иностранных сайтов будут довольно бедными.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Пособие по журналистике данных»
Представляем Вашему вниманию похожие книги на «Пособие по журналистике данных» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Пособие по журналистике данных» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.