The Handbook of Speech Perception
Здесь есть возможность читать онлайн «The Handbook of Speech Perception» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:The Handbook of Speech Perception
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
The Handbook of Speech Perception: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «The Handbook of Speech Perception»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
, Second Edition, is a comprehensive and up-to-date survey of technical and theoretical developments in perceptual research on human speech. Offering a variety of perspectives on the perception of spoken language, this volume provides original essays by leading researchers on the major issues and most recent findings in the field. Each chapter provides an informed and critical survey, including a summary of current research and debate, clear examples and research findings, and discussion of anticipated advances and potential research directions. The timely second edition of this valuable resource:
Discusses a uniquely broad range of both foundational and emerging issues in the field Surveys the major areas of the field of human speech perception Features newly commissioned essays on the relation between speech perception and reading, features in speech perception and lexical access, perceptual identification of individual talkers, and perceptual learning of accented speech Includes essential revisions of many chapters original to the first edition Offers critical introductions to recent research literature and leading field developments Encourages the development of multidisciplinary research on speech perception Provides readers with clear understanding of the aims, methods, challenges, and prospects for advances in the field
, Second Edition, is ideal for both specialists and non-specialists throughout the research community looking for a comprehensive view of the latest technical and theoretical accomplishments in the field.
The Handbook of Speech Perception — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «The Handbook of Speech Perception», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Typically, studies of auditory‐perceptual organization have reported that listeners are sensitive to quite subtle properties in the formation of auditory groups. It is useful to consider an exemplary case, for the detailed findings of auditory amalgamation and segregation define the characteristics of the model and ultimately determine its applicability to speech. In a study of concurrent grouping of harmonically related tones by virtue of coincident onset, a variant of similarity in a temporal dimension, Dannenbring and Bregman (1978) reported that synchronized tones were grouped together, but a discrepancy as brief as 35 ms in lead or lag in one component was sufficient to disrupt coherence with other sensory constituents, and to split it into a separate stream. There are many similar cases documenting the exquisite sensitivity of the auditory sensory channel in segregating streams on the basis of slight departures from similarity: in frequency (Bregman & Campbell, 1971), in frequency change (Bregman & Doehring, 1984), in fundamental frequency (Steiger & Bregman, 1982), in common modulation (Bregman et al., 1985), in spectrum (Dannenbring & Bregman, 1976; Warren et al., 1969), due to brief interruptions (Miller & Licklider, 1950), in common onset/offset (Bregman & Pinker, 1978), in frequency continuity (Bregman & Dannenbring, 1973, 1977), and in melody and meter (Jones & Boltz, 1989); these are reviewed by Bregman (1990), Remez et al. (1994), and Remez & Thomas (2013).
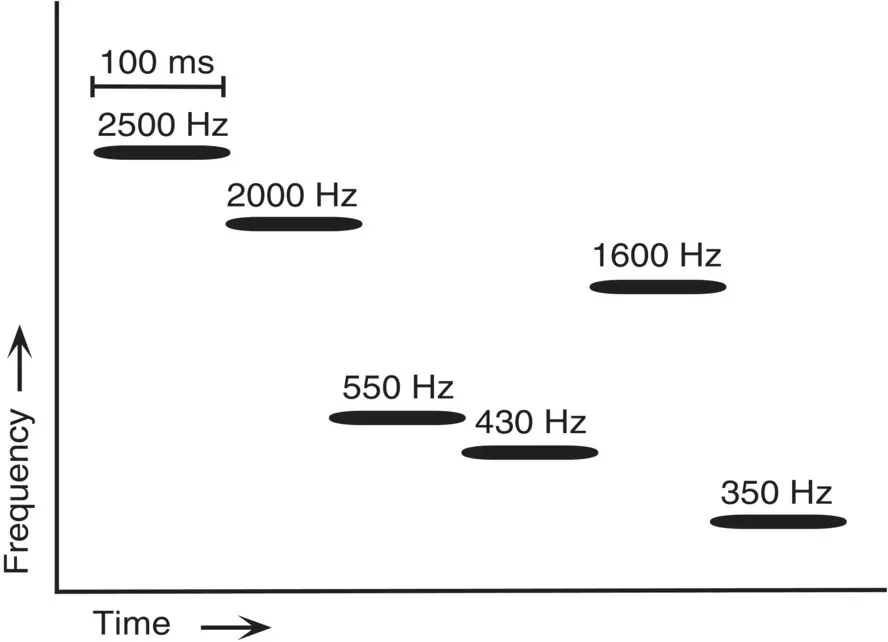
Figure 1.1 This sequence of tones presented to listeners by Bregman and Campbell (1971) was reported as two segregated streams, one of high and another of low tones. Critically, the intercalation of the high and low streams (that is, the sequence: high, high, low, low, high, low) was poorly resolved. Source: Based on Bregman & Campbell, 1971.
Gestalt principles of organization applied to speech.
Because explanations of speech perception have depended on an unspecified account of perceptual organization, it has been natural for auditory scene analysis to be a theory of first resort for understanding the perceptual solution to the cocktail party problem (Cherry, 1953; McDermott, 2009), specifically, of attending to a single stream of speech amid other sound sources. However, this premise was largely unsupported by direct evidence. The crucial empirical cases that had formed the model had rarely included natural sources of sound – neither instruments of the orchestra (though see Iverson, 1995), which are well modeled physically (Rossing, 1990), nor ordinary mechanical sources (Gaver, 1993), nor the sounds of speech, with several provocative exceptions. It is instructive to consider some of the cases in which tests of perceptual organization using speech sounds appeared to confirm the applicability to speech of the general auditory account of perceptual organization.
In one case establishing grouping by similarity, a repeating series of syllables of the form CV‐V‐CV‐V was observed to split into distinct streams of like syllables, one of CVs and another of Vs, much as gestalt principles propose (Lackner & Goldstein, 1974). Critically, this perceptual organization precluded the perceptual resolution of the relative order of the syllables across stream, analogous to the index of grouping used by Bregman & Campbell (1971). In another case calibrating grouping by continuity, a series of vowels formed a single perceptual stream only when formant frequency transitions leading into and out of the vowel nuclei were present (Dorman, Cutting, & Raphael, 1975). Without smooth transitions, the spectral discontinuity at the juncture between successive steady‐state vowels exceeded the tolerance for grouping by closure – that is, the interpolation of gaps – and the perceptual coherence of the vowel series was lost. In another case examining organization by the common fate, or similarity in change of a set of elements, a harmonic component of a steady‐state vowel close to the center frequency of a formant was advanced or delayed in onset relative to the rest of the harmonics composing the synthetic vowel (Darwin & Sutherland, 1984). At a lead or lag of 32 ms, consistent with findings deriving from arbitrary patterns, the desynchronized harmonic segregated into a different stream than the synchronous harmonics composing the vowel. In consequence, when the leading or lagging harmonic split, the phonemic height of the vowel was perceived to be different, as if the perceptual estimate of the center frequency of the first formant had depended on the grouping. In each of these instances, the findings with speech sounds were well explained by the precedents of prior tests using arbitrary patterns of sound created with oscillators and noise generators.
These outcomes should have seemed too good to be true. It was as if an account defined largely through tests of ideal notions of similarity in simple auditory sequences proved to be adequate to accommodate the diverse acoustic constituents and spectral patterns of natural sound. With hindsight, we can see that accepting this conclusion requires two credulous assumptions. One assumption is that tests using arbitrary trains of identical reduplicated syllables, meticulously phased harmonic components, and sustained steady‐state vowels adequately express the ordinary complexity of speech and the perceiver’s ordinary sensitivity. A sufficient test of organization by the generic principles of auditory scene analysis is more properly obliged to incorporate the kind of spectra that defined the technical description of speech perception. A closer approximation to the conditions of ordinary listening must characterize the empirical tests. Tests composed without imposing these assumptions reveal a set of functions rather different from the generic auditory model at work in the perceptual organization of speech.
A second assumption, obliged by the generic auditory account of organization is that the binding of sensory elements into a coherent contour, ready to analyze, occurs automatically, with neither attention nor effort. This premise had been asserted, though not secured by evidence. Direct attempts at an assay have been clear. These studies showed plainly that, whether a sound is speech or not, its acoustic products, sampled auditorily, are resolved into a contour distinct from the auditory background only by the application of attention (Carlyon et al., 2001, 2003; Cusack, Carlyon, & Robertson, 2001; Cusack et al., 2004). Without attention, contours fail to form and sounds remain within an undifferentiated background. Deliberate intention can also affect the listener’s integration or segregation of an element within an auditory sensory contour, by an application of attentional focus (for instance, Billig, Davis, & Carlyon, 2018)
The plausibility of the generic account of perceptual organization
A brief review of the acoustic properties of speech
One challenge of perceptual organization facing a listener is simple to state: to find and follow a speech stream. This would be an easy matter were the acoustic constituents of a speech signal or their auditory sensory correlates unique to speech, if the speech signal were more or less stationary in its spectrum, or if the acoustic elements and the auditory impressions they evoke were similar moment by moment. None of these is true, however, which inherently undermines the plausibility of any attempt to formalize the perceptual organization of speech as a task of determining successive or simultaneous similarities in auditory experience. First, the acoustic effects of speech are distributed across six octaves of audibility. The sensory contour of an utterance is widely distributed across frequency. Second, none of the multitude of naturally produced vocal sounds composing a speech signal is unique to speech. Arguably, the physical models of speech production succeed so well because they exploit an analogy between vocal sound and acoustic resonance (Fant, 1960; Stevens & House, 1961). Third, one signature aspect of speech is the presence of multiple acoustic maxima and minima in the spectrum, and the variation over time in the frequencies at which the acoustic energy is concentrated (Stevens & Blumstein, 1981). This frequency variation of the formant centers is interrupted at stop closures, creating an acoustic spectrum that is both nonstationary and discontinuous. Fourth, the complex pattern of articulation by which talkers produce consonant holds and approximations creates heterogeneous acoustic effects consisting of hisses, whistles, clicks, buzzes, and hums (Stevens, 1998). The resulting acoustic pattern of speech consists of a nonstationary, discontinuous series of periodic and aperiodic elements, none of which in detail is unique to a vocal source.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «The Handbook of Speech Perception»
Представляем Вашему вниманию похожие книги на «The Handbook of Speech Perception» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.







![О Генри - Справочник Гименея [The Handbook of Hymen]](/books/407356/o-genri-spravochnik-gimeneya-the-handbook-of-hymen-thumb.webp)




Обсуждение, отзывы о книге «The Handbook of Speech Perception» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.