Тревор Кокс - Зачем мы говорим. История речи от неандертальцев до искусственного интеллекта
Здесь есть возможность читать онлайн «Тревор Кокс - Зачем мы говорим. История речи от неандертальцев до искусственного интеллекта» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: М., Год выпуска: 2020, ISBN: 2020, Издательство: КоЛибри, Азбука-Аттикус, Жанр: sci_popular, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Зачем мы говорим. История речи от неандертальцев до искусственного интеллекта
- Автор:
- Издательство:КоЛибри, Азбука-Аттикус
- Жанр:
- Год:2020
- Город:М.
- ISBN:978-5-389-17812-0
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Зачем мы говорим. История речи от неандертальцев до искусственного интеллекта: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Зачем мы говорим. История речи от неандертальцев до искусственного интеллекта»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Зачем мы говорим. История речи от неандертальцев до искусственного интеллекта — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Зачем мы говорим. История речи от неандертальцев до искусственного интеллекта», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Но чтобы у компьютера появилась возможность обнаружить ложь, ему придется научиться понимать слова. Это позволит системе ориентироваться на другие признаки обмана, обнаруженные в научных исследованиях, например, на тот факт, что когда человек врет, он приводит меньше деталей и устанавливает меньше связей с внешними событиями {365} 365 Oberlader V. A., Naefgen C., Koppehele-Gossel J . Validity of content-based techniques to distinguish true and fabricated statements: A meta-analysis // Law and Human Behavior. 2016. Vol. 40 (4). P. 440.
. Но чтобы использовать эти данные, компьютеру нужно уметь распознавать речь и понимать ее семантику.
Одна из первых электронных систем распознавания речи, которая называлась «Одри», была создана в 1952 году К. Дэйвисом и его коллегами из Лабораторий Белла в США. Она могла распознавать отдельные цифры, а при тщательной настройке на конкретного говорящего правильно идентифицировала практически каждое слово. Как и другие первые системы, «Одри», по существу, работала по принципу подбора моделей. На рисунке выше показана запись голоса человека, который считает от одного до пяти. В верхней части — обычный способ представления звука, «виляющий» след, показывающий, как изменяется давление, создаваемое голосом, по мере произнесения пяти цифр. Второе слово, two , показывает два отдельных отрывка, [t] и [oo]. Оно начинается с взрывного [t], при котором воздух сначала блокируется языком, прижатым кверху, к нёбу, а когда язык отрывается, резкий выдох создает звук. За этим быстро следует гласный [oo], который почти пропевается. В нижней части — спектрограмма, показывающая изменение частотной характеристики речи. Для слова two темная линия опускается вниз слева направо, а для слова three видна диагональная темная линия, идущая в обратном направлении. Когда говорящий произносит вторую часть слова three , его интонация создает увеличение частоты, отсюда и идущая вверх линия на спектрограмме.
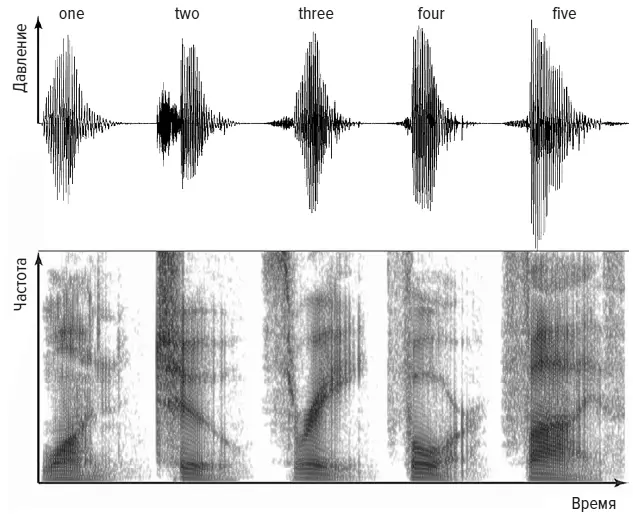
Мужской голос, считающий «one, two, three, four, five»
Спектрограммы подобны отпечаткам пальцев и показывают, что у каждой цифры уникальный рисунок. Задачей «Одри» было подобрать к образцу из произнесенного в микрофон звука пару из ожидаемых рисунков звука для каждой цифры. В 1950-е годы это было сложно реализовать, потому что для создания спектрограмм просто не было компьютеров. Более того, «Одри» была не слишком практичной системой. Джеймс Флэнаган из Лабораторий Белла вспоминал: «Она занимала релейную стойку шести футов (более 1,8 м) высотой, была ужасно дорогой, поглощала солидное количество энергии и создавала мириад проблем обслуживания, связанных со сложной ламповой схемой» {366} 366 Jim Flanagan et al. Techniques for expanding the capabilities of practical speech recognizers // Trends in Speech Recognition. 1980. Больше об Одри см.: Davis K. H., Biddulph R., Balashek S . Automatic recognition of spoken digits // Journal of the Acoustical Society of America. 1952. Vol. 24 (6). P. 637–642.
.
Еще одна проблема, связанная с подобным типом анализа, состоит в том, что человек не всегда одинаково произносит слова. Например, слово, которое обычно произносится с понижающейся частотой, в конце вопросительного предложения может произноситься с повышающейся интонацией. Кроме того, у разных людей произношение может сильно отличаться, так что ваша спектрограмма счета от одного до пяти будет отличаться от моей. Даже лучшие современные системы, которые используют значительно более изощренные технологии, чем «Одри», не срабатывают. Когда в 2011 году iPhone 4S появился на рынке Великобритании, голосовой помощник Siri с трудом понимал сильный шотландский акцент {367} 367 Say what? iPhone has problems with Scots accents // BBC. 2011. http://www.bbc.co.uk/news/uk-scotland-15475989 .
.
В последние годы появление мощных компьютеров и использование машинного обучения вполовину снизили количество ошибок при распознавании речи. Современные системы еще далеки от того, чтобы распознавать речь так же, как это делает человек, но им больше не требуется, чтобы вы говорили медленно и делали паузы между словами. Более того, в эпоху больших объемов данных эти системы обучаются на огромном количестве примеров. Именно так Apple решила проблемы с Siri: компьютер прослушал огромное количество записей шотландского произношения, чтобы его запомнить. Кроме того, большие объемы данных означают, что системы распознавания речи обладают огромным словарем — например, голосовой помощник Google претендует на знание примерно трех миллионов слов. Это значительно превышает возможности человека. Поэтому система распознавания речи будет работать, даже если вы прибегаете к очень узкой теме со своим специализированным набором слов.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Зачем мы говорим. История речи от неандертальцев до искусственного интеллекта»
Представляем Вашему вниманию похожие книги на «Зачем мы говорим. История речи от неандертальцев до искусственного интеллекта» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Зачем мы говорим. История речи от неандертальцев до искусственного интеллекта» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.