Макс Тегмарк - Жизнь 3.0. Быть человеком в эпоху искусственного интеллекта
Здесь есть возможность читать онлайн «Макс Тегмарк - Жизнь 3.0. Быть человеком в эпоху искусственного интеллекта» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2019, ISBN: 2019, Издательство: Литагент Corpus, Жанр: Прочая научная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Жизнь 3.0. Быть человеком в эпоху искусственного интеллекта
- Автор:
- Издательство:Литагент Corpus
- Жанр:
- Год:2019
- Город:Москва
- ISBN:978-5-17-105999-6
- Рейтинг книги:3 / 5. Голосов: 2
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Жизнь 3.0. Быть человеком в эпоху искусственного интеллекта: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Жизнь 3.0. Быть человеком в эпоху искусственного интеллекта»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Жизнь 3.0. Быть человеком в эпоху искусственного интеллекта — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Жизнь 3.0. Быть человеком в эпоху искусственного интеллекта», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Глава 3
Ближайшее будущее: болезни, законы, оружие и работа
Если мы не поспешим изменить направление, мы рискуем прибыть туда, откуда отбыли.
Ирвин КориЧто значит быть человеком в наше время? Например, что мы по-настоящему в себе ценим, что отличает нас от других форм жизни и от машин? Что другие люди ценят в нас, благодаря чему некоторые из них предлагают нам работу? Какие бы ответы на эти вопросы мы ни дали, ясно, что по мере развития технологий нам придется со временем изменять их.
Возьмите, например, меня. Как ученый я горжусь тем, что смог поставить перед собой собственные цели, мне достало ума и интуиции, чтобы решить довольно много не решенных до меня задач, и я сумел воспользоваться языком, чтобы сообщить о своих находках другим. К счастью для меня, общество оказалось готово заплатить мне за эту работу. Столетия назад я мог бы, наверное, как и многие другие, построить свою идентичность фермера или ремесленника, но с тех пор развитие технологий сильно сократило область, занимаемую такими профессиями. Это означает, что теперь стало невозможно каждому строить свою идентичность в сельском хозяйстве или в ремеслах.
Лично меня совсем не беспокоит, что сегодняшние машины превосходят меня в навыках ручного труда – в копании или вязании: для меня это не хобби, не источник дохода и не повод собою гордиться. В самом деле, любые иллюзии, которые могли у меня возникнуть по этому поводу, разбились, когда мне было всего восемь лет: у меня были уроки вязания в школе, показавшие мою полную неспособность к этому делу, и я смог хоть как-то справиться с данным мне заданием только благодаря помощи сострадательной пятиклассницы, сжалившейся надо мной.
Но если технологии будут продолжать развиваться, не случится ли так, что AI со временем превзойдет людей также и в том, чем я горжусь сейчас и за что меня ценят на рынке труда? Стюарт Рассел признавался мне, как ему с коллегами довелось недавно испытать момент искушения “выразиться по матушке”, когда они вдруг стали свидетелями такого, чего не ожидали от искусственного интеллекта еще много-много лет. Позвольте, пожалуйста, и мне рассказать вам о некоторых подобных моментах, в которых я вижу грядущую победу над многими из человеческих способностей.
Прорывы
В 2014 году, когда я смотрел видео, на котором разработанная DeepMind система с искусственным интеллектом училась играть в компьютерные игры, у меня отвисла челюсть. В особенности хорошо искусственному интеллекту удавалось играть в Breakout (см. рис. 3.1), классическую игру Atari, с нежностью вспоминаемую мной с подросткового возраста. Цель игры в том, чтобы, перемещая платформу, заставлять шарик биться о кирпичную стену. Всякий раз, когда удается выбить из стены кирпич, он пропадает, а счет увеличивается.
В тот день я написал несколько компьютерных игр, и хорошо знал, что написать программу, которая может сыграть в Breakout, совсем не трудно, но это было не то, что сделала команда DeepMind. Они сделали другое: создали девственно чистый AI, который ничего не знал об этой игре, как и о любых других играх, и вдобавок не имел никакого понятия о том, что такое игры, платформы, кирпичи или шарики. Их AI знал лишь одно: длинный список чисел, загружающихся через равные интервалы времени и представляющих текущий счет, и еще один длинный список, которые мы (но не AI) интерпретировали бы как описание цвета и освещенности разных частей экрана. AI просто велели максимизировать счет, выставляя с регулярными интервалами числа, которые мы (но не AI) будем распознавать как коды, соответствующие определенным нажатиям клавиш.
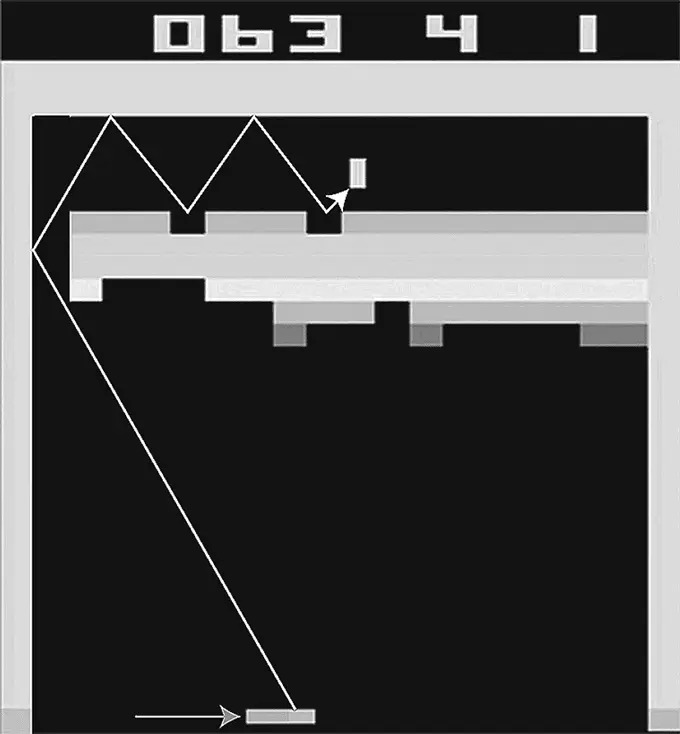
Рис. 3.1
Искусственный интеллект DeepMind учился проходить аркадную игру Breakout на платформе Atari с нуля, для чего использовались методы машинного обучения с подкреплением. Вскоре DeepMind самостоятельно открыл оптимальную стратегию: пробивать в левом краю кирпичной стены дыру и загонять в эту дыру игровой шарик, который, оказавшись в замкнутом пространстве, быстро увеличивает счет. Я добавил на этом рисунке стрелки, показывающие траектории платформы и шарика.
Поначалу AI играл ужасно: он бессмысленно толкал платформу влево и вправо, как слепой, почти каждый раз промахиваясь мимо шарика. В какой-то момент у него, казалось, возникла идея, что двигать платформу по направлению к шарику – это, наверное, правильно, но шарик все равно пролетал мимо. Мастерство AI, однако, продолжало расти с практикой, и вскоре он стал играть значительно лучше, чем я когда бы то ни было, безошибочно отбивая шарик, как бы быстро тот ни двигался. И тут-то и пришло время моей челюсти отвиснуть: AI непостижимым образом смог раскрыть знакомую мне стратегию максимизации очков: всегда целиться в верхний левый угол, чтобы, пробив дырку в кирпичной кладке, загонять шарик туда, позволяя ему там долго прыгать между тыльной стороной стены и границей игрового поля. Это действительно казалось разумным решением. Позже Демис Хассабис говорил мне, что программисты компании DeepMind не знали этого трюка, пока созданный ими искусственный интеллект не открыл им глаза. Я всем рекомендую посмотреть этот ролик, перейдя по ссылке, которую я здесь привожу {8} 8 DeepMind алгоритм глубокого машинного обучения с подкреплением позволил довольно быстро научиться играть в Breakout: https://tinyurl.com/atariai
.
Интервал:
Закладка:
Похожие книги на «Жизнь 3.0. Быть человеком в эпоху искусственного интеллекта»
Представляем Вашему вниманию похожие книги на «Жизнь 3.0. Быть человеком в эпоху искусственного интеллекта» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Жизнь 3.0. Быть человеком в эпоху искусственного интеллекта» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.