Ray Kurzweil - How to Create a Mind - The Secret of Human Thought Revealed
Здесь есть возможность читать онлайн «Ray Kurzweil - How to Create a Mind - The Secret of Human Thought Revealed» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Год выпуска: 2012, ISBN: 2012, Издательство: Penguin, Жанр: Прочая научная литература, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:How to Create a Mind: The Secret of Human Thought Revealed
- Автор:
- Издательство:Penguin
- Жанр:
- Год:2012
- ISBN:0670025291
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
How to Create a Mind: The Secret of Human Thought Revealed: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «How to Create a Mind: The Secret of Human Thought Revealed»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Now, in his much-anticipated How to Create a Mind, he takes this exploration to the next step: reverse-engineering the brain to understand precisely how it works, then applying that knowledge to create vastly intelligent machines.
Drawing on the most recent neuroscience research, his own research and inventions in artificial intelligence, and compelling thought experiments, he describes his new theory of how the neocortex (the thinking part of the brain) works: as a self-organizing hierarchical system of pattern recognizers. Kurzweil shows how these insights will enable us to greatly extend the powers of our own mind and provides a roadmap for the creation of superintelligence—humankind's most exciting next venture. We are now at the dawn of an era of radical possibilities in which merging with our technology will enable us to effectively address the world’s grand challenges.
How to Create a Mind is certain to be one of the most widely discussed and debated science books in many years—a touchstone for any consideration of the path of human progress.
How to Create a Mind: The Secret of Human Thought Revealed — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «How to Create a Mind: The Secret of Human Thought Revealed», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
By way of context, I had predicted in my first book, The Age of Intelligent Machines , written in the mid-1980s, that a computer would take the world chess championship by 1998. I also predicted that when that happened, we would either downgrade our opinion of human intelligence, upgrade our opinion of machine intelligence, or downplay the importance of chess, and that if history was a guide, we would minimize chess. Both of these things happened in 1997. When IBM’s chess supercomputer Deep Blue defeated the reigning human world chess champion, Garry Kasparov, we were immediately treated to arguments that it was to be expected that a computer would win at chess because computers are logic machines, and chess, after all, is a game of logic. Thus Deep Blue’s victory was judged to be neither surprising nor significant. Many of its critics went on to argue that computers would never master the subtleties of human language, including metaphors, similes, puns, double entendres, and humor.
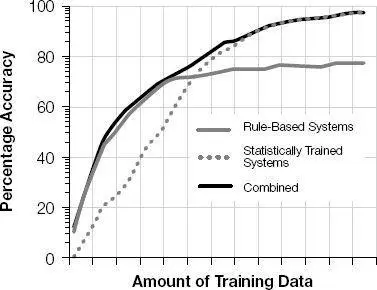
The accuracy of natural-language-understanding systems as a function of the amount of training data. The best approach is to combine rules for the “core” of the language and a data-based approach for the “tail” of the language.
That is at least one reason why Watson represents such a significant milestone: Jeopardy! is precisely such a sophisticated and challenging language task. Typical Jeopardy! queries includes many of these vagaries of human language. What is perhaps not evident to many observers is that Watson not only had to master the language in the unexpected and convoluted queries, but for the most part its knowledge was not hand-coded. It obtained that knowledge by actually reading 200 million pages of natural-language documents, including all of Wikipedia and other encyclopedias, comprising 4 trillion bytes of language-based knowledge. As readers of this book are well aware, Wikipedia is not written in LISP or CycL, but rather in natural sentences that have all of the ambiguities and intricacies inherent in language. Watson needed to consider all 4 trillion characters in its reference material when responding to a question. (I realize that Jeopardy! queries are answers in search of a question, but this is a technicality—they ultimately are really questions.) If Watson can understand and respond to questions based on 200 million pages—in three seconds!—there is nothing to stop similar systems from reading the other billions of documents on the Web. Indeed, that effort is now under way.
When we were developing character and speech recognition systems and early natural-language-understanding systems in the 1970s through 1990s, we used a methodology of incorporating an “expert manager.” We would develop multiple systems to do the same thing but would incorporate somewhat different approaches in each one. Some of the differences were subtle, such as variations in the parameters controlling the mathematics of the learning algorithm. Some variations were fundamental, such as including rule-based systems instead of hierarchical statistical learning systems. The expert manager was itself a software program that was programmed to learn the strengths and weaknesses of these different systems by examining their performance in real-world situations. It was based on the notion that these strengths were orthogonal; that is, one system would tend to be strong where another was weak. Indeed, the overall performance of the combined systems with the trained expert manager in charge was far better than any of the individual systems.
Watson works the same way. Using an architecture called UIMA (Unstructured Information Management Architecture), Watson deploys literally hundreds of different systems—many of the individual language components in Watson are the same ones that are used in publicly available natural-language-understanding systems—all of which are attempting to either directly come up with a response to the Jeopardy! query or else at least provide some disambiguation of the query. UIMA is basically acting as the expert manager to intelligently combine the results of the independent systems. UIMA goes substantially beyond earlier systems, such as the one we developed in the predecessor company to Nuance, in that its individual systems can contribute to a result without necessarily coming up with a final answer. It is sufficient if a subsystem helps narrow down the solution. UIMA is also able to compute how much confidence it has in the final answer. The human brain does this also—we are probably very confident of our response when asked for our mother’s first name, but we are less so in coming up with the name of someone we met casually a year ago.
Thus rather than come up with a single elegant approach to understanding the language problem inherent in Jeopardy! the IBM scientists combined all of the state-of-the-art language-understanding modules they could get their hands on. Some use hierarchical hidden Markov models; some use mathematical variants of HHMM; others use rule-based approaches to code directly a core set of reliable rules. UIMA evaluates the performance of each system in actual use and combines them in an optimal way. There is some misunderstanding in the public discussions of Watson in that the IBM scientists who created it often focus on UIMA, which is the expert manager they created. This leads to comments by some observers that Watson has no real understanding of language because it is difficult to identify where this understanding resides. Although the UIMA framework also learns from its own experience, Watson’s “understanding” of language cannot be found in UIMA alone but rather is distributed across all of its many components, including the self-organizing language modules that use methods similar to HHMM.
A separate part of Watson’s technology uses UIMA’s confidence estimate in its answers to determine how to place Jeopardy! bets. While the Watson system is specifically optimized to play this particular game, its core language- and knowledge-searching technology can easily be adapted to other broad tasks. One might think that less commonly shared professional knowledge, such as that in the medical field, would be more difficult to master than the general-purpose “common” knowledge that is required to play Jeopardy! Actually, the opposite is the case: Professional knowledge tends to be more highly organized, structured, and less ambiguous than its commonsense counterpart, so it is highly amenable to accurate natural-language understanding using these techniques. As mentioned, IBM is currently working with Nuance to adapt the Watson technology to medicine.
The conversation that takes place when Watson is playing Jeopardy! is a brief one: A question is posed, and Watson comes up with an answer. (Again, technically, it comes up with a question to respond to an answer.) It does not engage in a conversation that would require tracking all of the earlier statements of all participants. (Siri actually does do this to a limited extent: If you ask it to send a message to your wife, it will ask you to identify her, but it will remember who she is for subsequent requests.) Tracking all of the information in a conversation—a task that would clearly be required to pass the Turing test—is a significant additional requirement but not fundamentally more difficult than what Watson is doing already. After all, Watson has read hundreds of millions of pages of material, which obviously includes many stories, so it is capable of tracking through complicated sequential events. It should therefore be able to follow its own conversations and take that into consideration in its subsequent replies.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «How to Create a Mind: The Secret of Human Thought Revealed»
Представляем Вашему вниманию похожие книги на «How to Create a Mind: The Secret of Human Thought Revealed» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «How to Create a Mind: The Secret of Human Thought Revealed» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.