Вадим Гребенников - Криптология и секретная связь. Сделано в СССР
Здесь есть возможность читать онлайн «Вадим Гребенников - Криптология и секретная связь. Сделано в СССР» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2017, ISBN: 2017, Издательство: Алгоритм, Жанр: История, Прочая научная литература, military_special, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Криптология и секретная связь. Сделано в СССР
- Автор:
- Издательство:Алгоритм
- Жанр:
- Год:2017
- Город:Москва
- ISBN:978-5-906979-79-7
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Криптология и секретная связь. Сделано в СССР: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Криптология и секретная связь. Сделано в СССР»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
В книге подробно рассказано об истории зарождения и эволюции криптологии и специальной («закрытой») связи в Советском Союзе и современной России. Герои и предатели в этих сферах. История разработки и создания шифраторов и другого специального оборудования для защиты от «прослушки» различных видов связи. Как советская разведка охотилась за шифрами и кодами врага и каких успехов достигла.
Криптология и секретная связь. Сделано в СССР — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Криптология и секретная связь. Сделано в СССР», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Алфавит в этих шифрах мог быть русским или латинским, в зависимости от того, на каком языке писалось сообщение. Слоги постоянны и характерны для каждого языка, поэтому эти разделы шифров для каждого языка были одинаковы. Например, для русских шифров это были: ба, бе, бы, бо, бу, бы, бя, ва, ве, вы, во, ву, вы, вя и т. п.
Суплемент был достаточно большим и включал не только необходимые имена царственных персон, государственных деятелей («персоны») и географические названия, как это было ранее, но и другую активную лексику. В этот раздел, например, могли входить слова: домогательство, склонность и т. п.
Раздел «счеты», или, как его еще называли, «исчисления», как правило, во всех кодах был одинаков. Он включал такие величины: 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 00, 000, 0000, 00000, миллион. Иногда этот раздел как-то дополнялся, например, могли быть прибавлены числа 50 000 и 100 000.
Месяцы также перечислялись в особом разделе, и почти во всех шифрах это объяснялось так: «Месяцы для того особливыми литерами изображены, чтоб оные употреблять, когда в контексте нужда востребует, а инако в обыкновенном месте датума писать не надлежит».
За редким исключением шифробозначения — это арабские цифры. Цифры как шифробозначения для разных частей словаря всегда имели отличия. Например, если для алфавита они могли быть одно-, двух-, трехзначные, то для «суплемента» — только трех- или четырехзначные, а для других частей (месяцы, счеты) только четырехзначные. Кроме того, могли быть и другие отличия. Так, если для алфавита и «суплемента» шифробозначениями могли быть разные числа, то для других разделов — лишь числа, которые заканчивались нулями: 700, 750, 720, 4000 и т. п. Вообще для каждой последующей части словаря характерна была все растущая значимость шифробозначений.
Эти шифры имели большое количество пустышек, которые вводились с целью усложнения шифра. Могли вводиться ошибочные дополнительные цифры, которые также не имели смысла, но не входили в число пустышек. В правилах пользования шифрами, хотя они были еще очень короткими, явно проступала тенденция к использованию при шифровании даже небольших текстов основной части или даже большинства словарных величин. Как шифробозначения использовались почти исключительно цифры в отличие от шифров первой четверти века, когда в этой роли чаще выступали разные идеограммы. В новом типе шифров они применялись крайне редко и лишь для обозначения «персон».
Однако вместе с этими шифрами продолжали активно использоваться и шифры старых образцов, в которых был лишь алфавит с шифробозначениями, — цифрами, буквами или причудливыми старинными идеограммами, такими, например, как в ранней «Цифирной азбуке» для переписки с Григорием Волковым и князем Куракиным.
Разработчики шифров в этот период уже знали, что частота использования гласных букв в языке более высокая, чем согласных. Поэтому в 1730–1740-е годы в новых шифрах гласным обязательно соответствовало по нескольку шифробозначений, а согласным — одно-два. Наблюдались попытки записи шифротекста без разделения шифробозначений точками (что раньше было абсолютно исключено) или с разделением их фальшивыми точками. Способ дешифровки в правилах оговаривался заранее. Пример такого шифрования приведен в «Цифирной азбуке» для переписки с государственным вице-канцлером графом Воронцовым.
Это был шифр простой замены, где буквам кириллицы соответствовали двузначные цифровые шифробозначения, причем гласным было прибавлено по шесть шифробозначений, а согласным — по два. В правилах сказано: «Сею цифирью писать двояким образом, без точек, и с фальшивыми точками, которые как бы расставлены ни были, токмо для разбору всегда по два номера брать надлежит».
Шифробозначения в этот период выбирались всегда по определенным порядковым алфавитным схемам, что обычно не способствовало надежности шифров. Например, этот шифр выглядел так:
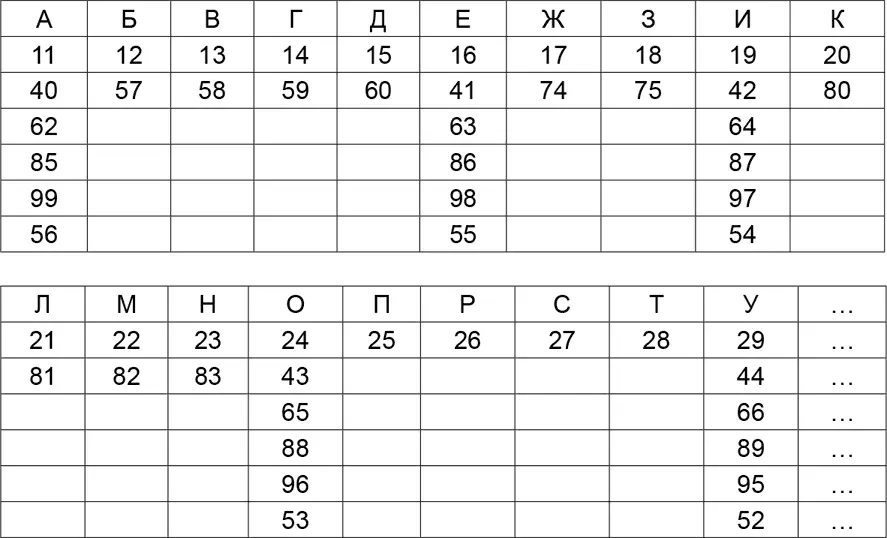
Слово «УЖГОРОД» можно зашифровать так: 441.7592. 426. 5.315; 8.974.1.488.266.560 и т. п.
С начала 1730-х годов в России наблюдался переход от алфавитных кодов к неалфавитным. В алфавитных кодах открытый текст и шифробозначения (собственно код) нумеровались параллельно друг другу. Отклонения от этого порядка хотя и были, но практически очень незначительные и мало влияли на повышение надежности или, как принято говорить, стойкости кода. По-видимому, разработчики шифров отметили, что такой параллелизм существенно облегчал восстановление открытого текста и самого кода, поскольку правильное угадывание некоторого числа шифробозначений позволяло упорядочить в алфавите шифробозначения других словарных величин.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Криптология и секретная связь. Сделано в СССР»
Представляем Вашему вниманию похожие книги на «Криптология и секретная связь. Сделано в СССР» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.



![Вадим Гребенников - Американская криптология [История спецсвязи]](/books/417207/vadim-grebennikov-amerikanskaya-kriptologiya-istori-thumb.webp)








Обсуждение, отзывы о книге «Криптология и секретная связь. Сделано в СССР» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.