Алексей Молчанов - Системное программное обеспечение. Лабораторный практикум
Здесь есть возможность читать онлайн «Алексей Молчанов - Системное программное обеспечение. Лабораторный практикум» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Санкт-Петербург, Год выпуска: 2005, ISBN: 2005, Издательство: Array Издательство «Питер», Жанр: Программирование, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Системное программное обеспечение. Лабораторный практикум
- Автор:
- Издательство:Array Издательство «Питер»
- Жанр:
- Год:2005
- Город:Санкт-Петербург
- ISBN:978-5-469-00391-4
- Рейтинг книги:4 / 5. Голосов: 2
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Системное программное обеспечение. Лабораторный практикум: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Системное программное обеспечение. Лабораторный практикум»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Книга ориентирована на студентов, обучающихся в технических вузах по специальностям, связанным с вычислительной техникой. Но она будет также полезна всем, чья деятельность так или иначе касается разработки программного обеспечения.
Системное программное обеспечение. Лабораторный практикум — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Системное программное обеспечение. Лабораторный практикум», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
В дальнейшем будем исходить из предположения, что все лексемы могут быть однозначно выделены сканером на этапе лексического анализа. Для всех современных языков программирования это действительно так, поскольку их синтаксис разрабатывался с учетом возможностей компиляторов.
Таблица лексем и содержащаяся в ней информация
Результатом работы лексического анализатора является перечень всех найденных в тексте исходной программы лексем с учетом характеристик каждой лексемы. Этот перечень лексем можно представить в виде таблицы, называемой таблицей лексем. Каждой лексеме в таблице лексем соответствует некий уникальный условный код, зависящий от типа лексемы, и дополнительная служебная информация. Таблица лексем в каждой строке должна содержать информацию о виде лексемы, ее типе и, возможно, значении. Обычно структуры данных, служащие для организации такой таблицы, имеют два поля: первое – тип лексемы, второе – указатель на информацию о лексеме.
Кроме того, информация о некоторых типах лексем, найденных в исходной программе, должна помещаться в таблицу идентификаторов (или в одну из таблиц идентификаторов, если компилятор предусматривает различные таблицы идентификаторов для различных типов лексем).
Внимание!
Не следует путать таблицу лексем и таблицу идентификаторов – это две принципиально разные таблицы, обрабатываемые лексическим анализатором.
Таблица лексем фактически содержит весь текст исходной программы, обработанный лексическим анализатором. В нее входят все возможные типы лексем, кроме того, любая лексема может встречаться в ней любое количество раз. Таблица идентификаторов содержит только определенные типы лексем – идентификаторы и константы. В нее не попадают такие лексемы, как ключевые (служебные) слова входного языка, знаки операций и разделители. Кроме того, каждая лексема (идентификатор или константа) может встречаться в таблице идентификаторов только один раз. Также можно отметить, что лексемы в таблице лексем обязательно располагаются в том же порядке, что и в исходной программе (порядок лексем в ней не меняется), а в таблице идентификаторов лексемы располагаются в любом порядке так, чтобы обеспечить удобство поиска.
В качестве примера можно рассмотреть некоторый фрагмент исходного кода на языке Object Pascal и соответствующую ему таблицу лексем, представленную в табл. 2.1:
…
begin
for i:=1 to N do
fg:= fg * 0.5
…
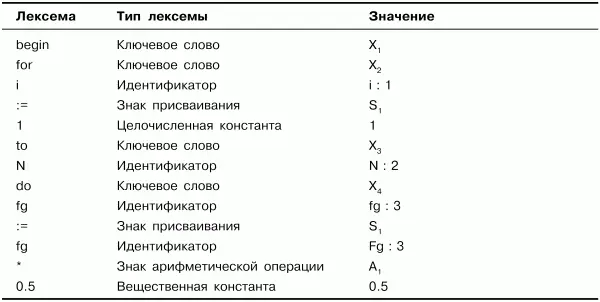
Поле «значение» в табл. 2.1 подразумевает некое кодовое значение, которое будет помещено в итоговую таблицу лексем в результате работы лексического анализатора. Конечно, значения, которые записаны в примере, являются условными. Конкретные коды выбираются разработчиками при реализации компилятора. Важно отметить также, что устанавливается связь таблицы лексем с таблицей идентификаторов (в примере это отражено некоторым индексом, следующим после идентификатора за знаком «:», а в реальном компиляторе определяется его реализацией).
Построение лексических анализаторов (сканеров)
Лексический анализатор имеет дело с такими объектами, как различного рода константы и идентификаторы (к последним относятся и ключевые слова). Язык описания констант и идентификаторов в большинстве случаев является регулярным, то есть может быть описан с помощью регулярных грамматик [1–4, 7]. Распознавателями для регулярных языков являются конечные автоматы (КА). Существуют правила, с помощью которых для любой регулярной грамматики может быть построен КА, распознающий цепочки языка, заданного этой грамматикой.
Более подробно о построении КА на основе грамматик для регулярных языков можно узнать в [3, 7, 26].
Любой КА может быть задан с помощью пяти параметров: M(Q,Σ,δ,q 0,F),
где:
Q – конечное множество состояний автомата;
Σ – конечное множество допустимых входных символов (входной алфавит КА);
δ – заданное отображение множества Q·Σ во множество подмножеств P(Q)δ: Q·Σ → P(Q) (иногда δ называют функцией переходов автомата);
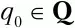
– начальное состояние автомата;
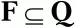
– множество заключительных состояний автомата.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Системное программное обеспечение. Лабораторный практикум»
Представляем Вашему вниманию похожие книги на «Системное программное обеспечение. Лабораторный практикум» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.









Обсуждение, отзывы о книге «Системное программное обеспечение. Лабораторный практикум» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.