У Клоксин - ПРОГРАММИРОВАНИЕ НА ЯЗЫКЕ ПРОЛОГ
Здесь есть возможность читать онлайн «У Клоксин - ПРОГРАММИРОВАНИЕ НА ЯЗЫКЕ ПРОЛОГ» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: Программирование, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.
- Название:ПРОГРАММИРОВАНИЕ НА ЯЗЫКЕ ПРОЛОГ
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
ПРОГРАММИРОВАНИЕ НА ЯЗЫКЕ ПРОЛОГ: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «ПРОГРАММИРОВАНИЕ НА ЯЗЫКЕ ПРОЛОГ»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
ПРОГРАММИРОВАНИЕ НА ЯЗЫКЕ ПРОЛОГ — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «ПРОГРАММИРОВАНИЕ НА ЯЗЫКЕ ПРОЛОГ», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Выигрыши(abaris,582).
Выигрыши(careful,17).
Выигрыши(jingling_silvee,300).
Bыигрыши(majola,356).
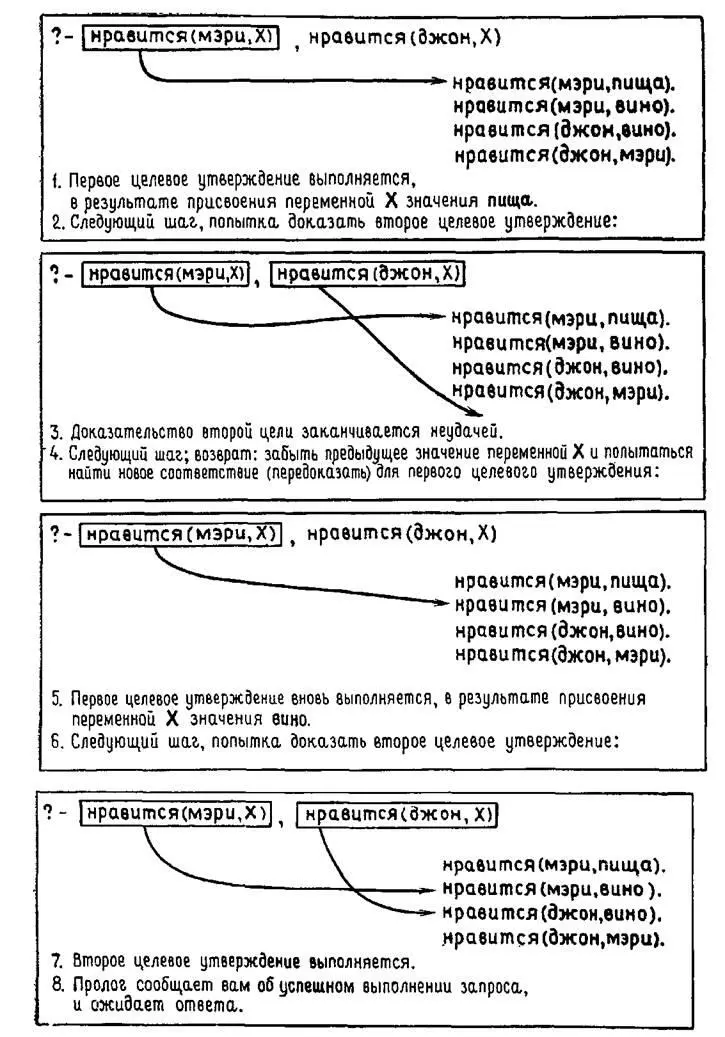
Если мы хотим узнать, какую сумму выиграла лошадь по кличке maloja,нам нужно просто правильно построить вопрос и Пролог даст нам ответ:
?- Bыигрыши(maloja, X).
X=356
Напомним, что Пролог просматривает базу данных сверху вниз. Это значит, что если база данных нашего словаря упорядочена в алфавитном порядке, как в приведенном выше примере, то на поиск суммы выигрыша для ablazeПролог затратит меньше времени, чем на поиск суммы выигрыша для zoltan.Однако хотя Пролог способен просмотреть свою базу данных гораздо быстрее, чем вы сможете просмотреть напечатанную таблицу, неразумно просматривать таблицу с начала до конца, если известно, что данные искомой лошади расположены в самом конце. Точно так же, хотя в Прологе имеются специальные средства быстрого просмотра базы данных, он не всегда проходит так быстро, как хотелось бы. В зависимости от размеров таблицы и от того, сколько информации хранится о каждой лошади, Прологу может потребоваться на просмотр таблицы неприемлемо большое время.
По этим и другим причинам специалисты по информатике потратили немало сил на поиски хороших способов организации хранения таких данных, как таблицы и словари. Сам Пролог использует некоторые из этих методов внутри себя при организации хранения своих собственных фактов и правил, но иногда их полезно использовать и в наших программах. Мы рассмотрим один такой метод организации словаря, который называется методом упорядоченного дерева. Метод упорядоченного дерева является одновременно и эффективным способом использования словаря и средством демонстрации того, насколько полезны списки структур.
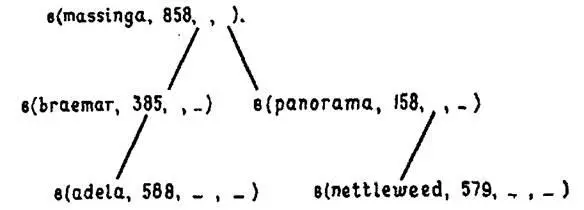
Рис. 7.1.
Упорядоченное дерево состоит из некоторого числа структур, называемых узлами, причем каждому входу словаря соответствует один узел. Каждый узел содержит четыре компоненты. Сюда входят два связанных с узлом элемента данных, как в предикате выигрышив вышеприведенном примере. Один из этих элементов называется ключом, его имя определяет место в словаре (кличка лошади в нашем примере). Другой элемент используется для хранения какой-либо другой информации о данном объекте (сумма выигрыша в нашем примере). Кроме того, каждый узел содержит ссылку (наподобие ссылки на хвост списка) на узел со значением ключа, которое лексикографически (по алфавиту) меньше, чем имя, являющееся ключом данного узла, а также еще одну ссылку на узел со значением ключа лексикографически большим, чем имя, являющееся ключом данного узла. Будем использовать структуру, которую обозначим как в(Л,В,М, Б) (в- сокращение от «выигрыши»), где Л– кличка лошади (атом), используемая в качестве ключа, В– сумма выигрыша в гинеях (целое), М– структура, соответствующая лошади, кличка которой меньше, чем та, что хранится в Л, а Б – структура, соответствующая лошади, кличка которой больше, чем значение в Л. Когда для Ми Бнет соответствующих структур, мы не будем их конкретизировать. Для небольшого множества лошадей указанная структура, будучи записанной в виде дерева, могла бы иметь вид, как представлено на рис. 7.1.
Если записать ее на Прологе в ступенчатом виде, учитывая ширину страницы, то она могла бы выглядеть так:
в(massinga,858,
в(braermar,385,
в(adela,588,_,_),
_),
в(panorama,158,
в(nettleweed,579,_,_),
_).
).
Теперь, располагая такой структурой, мы хотим «просмотреть» ее по кличкам лошадей, чтобы узнать их выигрыши в течение 1938 г. Как и раньше, структура должна иметь формат в(Л,В,М, Б).Условие окончания поиска состоит в том, что кличка искомой лошади должна совпасть с Л. В этом случае поиск удачен и не требуется пробовать другие варианты. В противном случае мы должны использовать предикат меньше,определенный в гл. 3, чтобы определить, какую из «ветвей» дерева, Мили Б, нужно рекурсивно просмотреть. Мы используем эти принципы при определении предиката искать,причем искать(Л,Т, Г)означает, что лошадь Л, если она найдена в таблице Т (которая организована в виде структуры формата в), выиграла Ггиней:
искать (Л, в(Л,Г,_,),Г):- !.
искать Л, в(Л1,_,До,_),Г):-меньше(Л,Л1),искать(Л,До,Г).
Читать дальшеИнтервал:
Закладка:
Похожие книги на «ПРОГРАММИРОВАНИЕ НА ЯЗЫКЕ ПРОЛОГ»
Представляем Вашему вниманию похожие книги на «ПРОГРАММИРОВАНИЕ НА ЯЗЫКЕ ПРОЛОГ» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.










Обсуждение, отзывы о книге «ПРОГРАММИРОВАНИЕ НА ЯЗЫКЕ ПРОЛОГ» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.