TWDragon Array - Создание электронных книг из сканов. DjVu или Pdf из бумажной книги легко и быстро
Здесь есть возможность читать онлайн «TWDragon Array - Создание электронных книг из сканов. DjVu или Pdf из бумажной книги легко и быстро» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Год выпуска: 2009, Жанр: Программирование, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Создание электронных книг из сканов. DjVu или Pdf из бумажной книги легко и быстро
- Автор:
- Жанр:
- Год:2009
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Создание электронных книг из сканов. DjVu или Pdf из бумажной книги легко и быстро: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Создание электронных книг из сканов. DjVu или Pdf из бумажной книги легко и быстро»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Итак: перед вами взятая у приятеля, из библиотеки, или просто хорошая, интересная книга, которую хотелось бы иметь на компьютере. И не просто иметь, а иметь в таком виде, который позволил бы выполнять поиск по тексту, удобно читать книгу на экране монитора или на устройствах еВоок, а если это не научно-техническая или справочная литература – еще и читать на любимом сотовом телефоне, iPhon'e или PDA. В этом пошаговом руководстве, основанном на собственном опыте, я постараюсь рассказать о том, как «выжать» максимум результатов из проделанной простой, но иногда весьма утомительной работы по сканированию книги.
Пусть вас не испугает длина этого руководства и кажущаяся сложность сканирования и обработки книги. Процесс действительно довольно сложен и многоступенчат, но поверьте мне, описать все эти операции было гораздо труднее, чем выполнить их шаг за шагом.
Создание электронных книг из сканов. DjVu или Pdf из бумажной книги легко и быстро — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Создание электронных книг из сканов. DjVu или Pdf из бумажной книги легко и быстро», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:

Из личного опыта:
Поработав с несколькими десятками книг, я пришел к выводу, что нумерацию файлов со сканами лучше всего начинать с нуля (например, Scan_000.TIF). Дело в том. что нумерация страниц в книгах обычно идет по схеме: Форзац =› Страница 1 (как правило, без номера) =› Страница 2 (данные типографии) =› Прочие страницы. Если сканировать книгу разворотами, то при нумерации с нуля номер каждого файла будет в точности равен номеру четной страницы, разделенному на 2, то есть:
1. Разворот 1 (Форзац и страница номер 1) – файл с именем Scan_000. TIF;
2. Разворот 2 (страницы 2 и 3) – файл с именем Scan_001. TIF;
3. Разворот 3 (страницы 4 и 5) – файл с именем Scan 002. TIF;
4. Итак далее…
Как правило, сканы именует сама программа сканирования, когда включен ее пакетный режим. Тогда заботиться об именах вообще не нужно. Однако у меня автоматическое именование работает (причем плохо) – только когда включен модуль автоматического листового сканирования ScanJet ADF. Поэтому я стараюсь давать своим файлам вручную простейшие цифровые имена, набивая их на нумпаде (заодно руки отдыхают от постоянного нажатия Ctrl+S).
Облегчить себе работу при сканировании – максимально насущная задача.
Если сканирование каждого отдельного разворота/листа включается клавишами (например теми же Ctrl+S) – нет проблем. Просто не меняя параметров области сканирования – жмете клавиши еще раз, набираете (или не набираете, если повезло с программой) имя очередного файла – и ждете окончания процесса. Если же без нажатия кнопки мыши не обойтись – ставите курсор на кнопку включения сканирования, и по окончании прохода очередной страницы – щелкаете пальцем по мышке, не сдвигая ее. При этом дожидаться, пока головка сканера вернется в исходное положение – никак не обязательно! Это только замедлит работу.
Описанным способом, в зависимости от быстродействия сканера, на один разворот уходит в среднем 18-25 секунд. То есть, при небольшом навыке можно выйти на «производительность ударного труда» порядка 160-200 разворотов (360-400 страниц) в час. Это значит, что в среднем за пару часов вы способны управиться даже с самыми толстыми томами! Немного усидчивости – и вуаля.
Маленькие хитрости
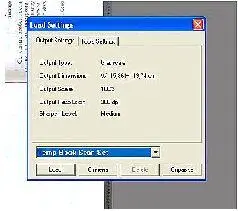
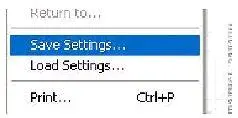
Крайне желательно, чтобы программа сканирования имела обновляемые пресеты установок области и параметров сканирования. Тогда, не закончив вечером работу над очередным томом, можно сохранить установки сканера, а потом – просто загрузить их.
В целом, чем проще будет для вас процесс сканирования – тем лучше. Главное для получения хорошего результата – следовать самым простым описанным правилам – получать выходной файл в формате несжатого TIFF, с разрешением 300dpi. Ну, и, само собой разумеется, в готовых файлах вы сами должны быть способны, не напрягаясь, прочитать текст.
Шаг 2. Пакетная обработка
После сканирования полученные файлы содержат страницы книги, иногда в довольно неприятном виде, вроде такого:

Смещенные и повернутые относительно друг друга страницы, низкий контраст, нечеткости печати во всей красе, затемненная область у корешка и полей – там, где книга неплотно прилегала к стеклу сканера. У такой страницы в неизмененном виде – мало шансов быть распознанной без ошибок, и тем более она не будет иметь никакого «товарного вида» после сжатия и упаковки в DjVu или PDF.
Устранить все дефекты и повысить качество распознавания текста – поможет пакетная обработка.
2.1 ScanKromsator V5.92
Салютуем альтруизму разработчиков-добровольцев!
Программа ScanKromsator 5.92(автор – уважаемый камрад bolega) – объективно лучший на данный момент процессор пакетной обработки изображений, специально «заточенный» под книгосканирование. Скачать программу всегда можно здесь: http://www.djvu-soft.narod.m/soft/ TWDragon, 4u4undr Создание электронных книг из сканов. DjVu или Pdf из бумажной книги легко и быстро Предисловие автора Итак: перед вами взятая у приятеля, из библиотеки, или просто хорошая, интересная книга, которую хотелось бы иметь на компьютере. И не просто иметь, а иметь в таком виде, который позволил бы выполнять поиск по тексту, удобно читать книгу на экране монитора или на устройствах еВоок, а если это не научно-техническая или справочная литература – еще и читать на любимом сотовом телефоне, iPhon'e или PDA. В этом пошаговом руководстве, основанном на собственном опыте, я постараюсь рассказать о том, как «выжать» максимум результатов из проделанной простой, но иногда весьма утомительной работы по сканированию книги. Пусть вас не испугает длина этого руководства и кажущаяся сложность сканирования и обработки книги. Процесс действительно довольно сложен и многоступенчат, но поверьте мне, описать все эти операции было гораздо труднее, чем выполнить их шаг за шагом. Итак, ПОЕХАЛИ!
.
Интервал:
Закладка:
Похожие книги на «Создание электронных книг из сканов. DjVu или Pdf из бумажной книги легко и быстро»
Представляем Вашему вниманию похожие книги на «Создание электронных книг из сканов. DjVu или Pdf из бумажной книги легко и быстро» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.







![Weeldoon - Попаданцы всех мастей [Аннотированный список электронных книг]](/books/414628/weeldoon-popadancy-vseh-mastej-annotirovannyj-spi-thumb.webp)




Обсуждение, отзывы о книге «Создание электронных книг из сканов. DjVu или Pdf из бумажной книги легко и быстро» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.