Роб Кёртен - Введение в QNX/Neutrino 2. Руководство по программированию приложений реального времени в QNX Realtime Platform
Здесь есть возможность читать онлайн «Роб Кёртен - Введение в QNX/Neutrino 2. Руководство по программированию приложений реального времени в QNX Realtime Platform» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Санкт-Петербург, Год выпуска: 2001, ISBN: 2001, Издательство: Петрополис, Жанр: Программирование, ОС и Сети, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.
- Название:Введение в QNX/Neutrino 2. Руководство по программированию приложений реального времени в QNX Realtime Platform
- Автор:
- Издательство:Петрополис
- Жанр:
- Год:2001
- Город:Санкт-Петербург
- ISBN:5-94656-025-9
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Введение в QNX/Neutrino 2. Руководство по программированию приложений реального времени в QNX Realtime Platform: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Введение в QNX/Neutrino 2. Руководство по программированию приложений реального времени в QNX Realtime Platform»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
В книге подробно описаны основные составляющие ОС QNX/Neutrino и их взаимосвязи. В частности, уделено особое внимание следующим темам:
• обмен сообщениями: принципы функционирования и основы применения;
• процессы и потоки: базовые концепции, предостережения и рекомендации;
• таймеры: организация периодических событий в программах;
• администраторы ресурсов: все, что относится к программированию драйверов устройств;
• прерывания: рекомендации по эффективной обработке.
В книге представлено множество проверенных примеров кода, подробных разъяснений и рисунков, которые помогут вам детально вникнуть в и излагаемый материал. Примеры кода и обновления к ним также можно найти на веб-сайте автора данной книги, www.parse.com.
Введение в QNX/Neutrino 2. Руководство по программированию приложений реального времени в QNX Realtime Platform — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Введение в QNX/Neutrino 2. Руководство по программированию приложений реального времени в QNX Realtime Platform», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Как упоминалось ранее, с функцией pthread_join() рабочие потоки для синхронизации главного потока с ними должны умереть. В случае же с барьером потоки живут и чувствуют себя вполне хорошо. Фактически, отработав, они просто разблокируются по функции barrier_wait() . Тонкость здесь в том, что вы обязаны предусмотреть, что эти потоки должны делать дальше! В нашем примере с графикой мы не дали им никакого задания для них — просто потому что мы так придумали алгоритм. В реальной жизни вы могли бы захотеть, например, продолжить вычисления.
Предположим, что мы слегка изменили наш пример так, чтобы можно было проиллюстрировать, почему иногда хорошо иметь несколько потоков даже в системе с одиночным процессором.
В таком модифицированном примере один узел на сети ответственен за вычисление строк растра (как и в примере с графикой, рассмотренном выше). Однако, когда строка рассчитана, ее данные должны быть отправлены по сети другому узлу, который выполняет функцию отображения. Ниже приведена соответствующая модифицированная функция main() (на основе первоначального примера без потоков):
int main(int argc, char **argv) {
int x1;
... // выполнить инициализации
for (x1 = 0; x1 < num_x_lines; x1++) {
do _one_line(x1); // Область «С» на схеме
tx_one_line_wait_ack(x1); // Области «X» и «W» на схеме
}
}
Обратите внимание на то, что мы исключили отображающую часть программы и вместо этого добавили функцию tx_one_line_wait_ack() . Далее предположим, что мы имеем дело с достаточно медленной сетью, но процессор в действительности не занимается передачей данных — он просто отдает их некоторым аппаратным средствам, которые уже сами позаботятся об их передаче. Функция tx_one_line_wait_ack() потребует немного процессорного времени на то, чтобы обеспечить передачу данных аппаратным средствам, и после этого, пока не получит подтверждения о получении данных от удаленного узла, не будет потреблять процессорное время вообще.
Ниже представлена диаграмма, иллюстрирующая загрузку процессора в данном случае (графические вычисления на ней обозначены как «С», передача — как «X», а ожидание подтверждения — как «W»).
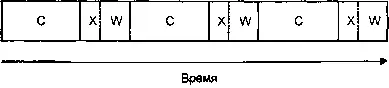
Последовательное выполнение, один процессор.
Минуточку! Мы тратим впустую драгоценные секунды, ожидая, пока аппаратура сделает свое дело!
Если мы сделали бы это в многопоточном варианте, мы смогли бы добиться более эффективного использования процессора, так?
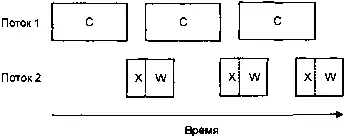
Многопоточное выполнение, один процессор
Это уже намного лучше, потому что теперь, даже при том, второй поток затрачивает немного времени на ожидание, мы добились уменьшения суммарного времени вычислений.
Если бы в нашем примере тратилось T computeединиц времени на вычисления, T tx — на передачу и T wait— на ожидание аппарату средств, тогда для первого случая в нашем примере общие затраты времени на обработку были бы равны:
(T compute+ T tx+ T wait) ∙ num_x_lines ,
тогда как затраты времени при использовании двух потоков были бы равны:
(T compute+ T tx) ∙ num_x_lines + T wait,
что меньше на величину:
T wait∙ ( num_x_lines – 1),
в предположении, конечно, что T wait≤ T compute.
 Отметим, что мы изначально будем ограничены интервалом времени, равным:
Отметим, что мы изначально будем ограничены интервалом времени, равным:
T compute+ T tx∙ num_x_lines ,
потому что мы должны будем завершить по меньшей мере одно полное вычисление, а также еще и передать данные. Иными словами, мы можем использовать многопоточность для распараллеливания вычислений, но аппаратный ресурс для передачи данных у нас все равно есть только один.
А если бы мы разработали вариант системы с четырьмя потоками и выполнили это в SMP-системе с четырьмя процессорами, это выглядело бы примерно так:
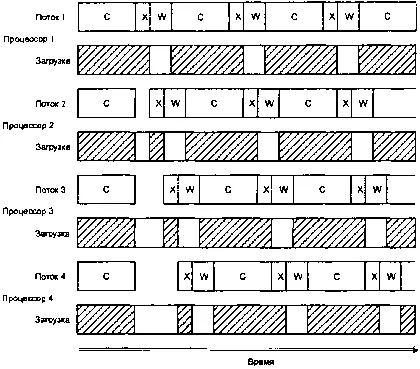
Четыре потока, четыре процессора.
Обратите внимание, насколько каждый из этих четырех центральных процессоров недоиспользован (см. незаштрихованные прямоугольники в строках «Загрузка»). На представленном выше рисунке имеются две интересные зоны. Когда все четыре потока стартуют одновременно, все они вычисляются. К сожалению, когда потоки заканчивают вычисления, они начинают конкурировать за право обладания аппаратными средствами передачи данных (зоны «X» на диаграмме смещены одна относительно другой, поскольку, имея только один передающий ресурс, можно вести только одну передачу одновременно). Это дает нам небольшую аномалию на начальном этапе. После того как потоки отработали этот этап, они оказываются естественным образом синхронизированы по отношению к работе аппаратных средств, так как время передачи данных намного меньше, чем ¼ времени вычислительного цикла. Если игнорировать эту небольшую аномалию в работе системы на начальном этапе, значения временных интервалов в данной системе можно оценить по формуле:
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Введение в QNX/Neutrino 2. Руководство по программированию приложений реального времени в QNX Realtime Platform»
Представляем Вашему вниманию похожие книги на «Введение в QNX/Neutrino 2. Руководство по программированию приложений реального времени в QNX Realtime Platform» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.









Обсуждение, отзывы о книге «Введение в QNX/Neutrino 2. Руководство по программированию приложений реального времени в QNX Realtime Platform» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.