Kris Kaspersky - Тонкости дизассемблирования
Здесь есть возможность читать онлайн «Kris Kaspersky - Тонкости дизассемблирования» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: Программирование, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.
- Название:Тонкости дизассемблирования
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Тонкости дизассемблирования: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Тонкости дизассемблирования»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Тонкости дизассемблирования — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Тонкости дизассемблирования», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Избежать проблем можно, лишь четко представляя себе сам принцип кодировки команд, а не просто работая с «мертвой» таблицей кодов операций, которую многие авторы вводят в дизассемблер и на том успокаиваются, так как внешне все работает правильно.
К тонкостям кодирования команд мы еще вернемся, а пока приготовимся к разбору поля modR/M. Два трехбитовых поля могут задавать код регистра общего назначения по следующей таблице (таблица 2):
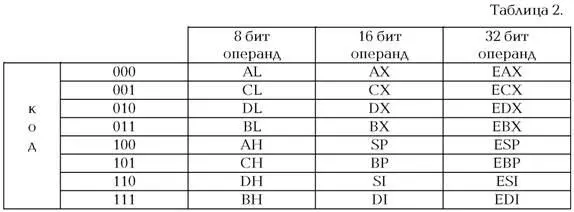
Опять можно восхищаться лаконичностью инженеров Intel, которые ухитрились всего в трех битах закодировать столько регистров. Это, кстати, объясняет, почему нельзя выборочно обращаться к старшим и младшим байтам регистров SР, BР, SI, DI и, аналогично, к старшему слову всех 32-битных регистров. Во всем «виновата» оптимизация и архитектура команд. Просто нет свободных полей, в которые можно было бы «вместить» дополнительные регистры. Сегодня мы вынуждены расхлебывать результаты архитектурных решений, выглядевшими такими удачными всего лишь десятилетие назад.
Обратите внимание на порядок регистров: AX, CX, DX, BX, SР, BР, SI, DI. Немного не по алфавиту, верно? И особенно странно в этом отношении выглядит регистр BX. Но, если понять причины, то никакой нужны запоминать это исключение не будет, т.к. все станет на свои места: BX — это индексный регистр, и первым стоит среди индексных.
Таким образом, мы уже можем «вручную» без дизассемблера распознавать в шестнадцатеричном дампе регистры-операнды. Очень неплохо для начала! Или писать самомодифицирующийся код. Например:

Он изменит 6 строку на XOR SP,SP. Это «завесит» многие отладчики, и, кроме того, не позволит дизассемблерам отслеживать локальные переменные адресуемые через SР. Хотя IDA Pro и позволяет скорректировать стек вручную, для этого надо сначала понять, что SР обнулился. В приведенном примере это очевидно (но в глаза, кстати, не бросается), а если это произойдет в многопоточной системе? Тогда изменение кода очень трудно будет отследить, особенно в листинге дизассемблера. Однако, нужно помнить, что самомодифицирующийся код все же уходит в историю. Сегодня он встречается все реже и реже.

Первоначально сегментные регистры кодировались всего двумя битами и этого с вполне хватало, т.к. их было всего четыре. Позже, когда количество их увеличилось, перешли на трехбитную кодировку. При этом две кодовые комбинации (110b и 111b) в настоящее время не применяются и вряд ли будут добавлены в ближайшем будущем. Но что же будет, если попытаться их использовать? Генерация INT 06h. А вот отладчики-эмуляторы могут вести себя странно. Одни не генерируют при этом прерывания, чем себя и выдают, а другие — ведут себя непредсказуемо, т.к. при этом требуемый регистр может находится в области памяти, занятой другой переменной (это происходит, когда ячейка памяти определяется по индексу регистра, при этом считываются три бита и суммируются с базой, но никак не проверяются пределы).

Кстати, IDA Pro вообще отказывается анализировать весь последующий код. Как это можно использовать? Да очень просто — если эмулировать еще два сегментных регистра в обработчике INT 06h, то очень трудно это будет как отлаживать, так и ди-зассемблировать программу. Однако, это опять-таки не работает под win32!
Управляющие/отладочные регистры кодируются нижеследующим образом:

Заметим, что коды операций mov, манипулирующих этими регистрами, различны, поэтому-то и возникает кажущееся совпадение имен. С управляющими регистрами связана одна любопытная мелочь. Регистр CR1, как известно большинству, в настоящее время зарезервирован и не используется. Во всяком случае, так написано в русскоязычной документации. На самом деле регистр CR1 просто не существует! И любая попытка обращения к нему вызывает генерацию исключение INT 06h. Например, cuр386 в режиме эмуляции процессора этого не учитывает и неверно исполняет программу. А все дизассемблеры, за исключением IDA Pro, неправильно дизассемблируют этот несуществующий регистр:
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Тонкости дизассемблирования»
Представляем Вашему вниманию похожие книги на «Тонкости дизассемблирования» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Тонкости дизассемблирования» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.