Б Бёрнс - Распределенные системы. Паттерны проектирования
Здесь есть возможность читать онлайн «Б Бёрнс - Распределенные системы. Паттерны проектирования» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Год выпуска: 2019, ISBN: 2019, Издательство: Питер, Жанр: Прочая околокомпьтерная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Распределенные системы. Паттерны проектирования
- Автор:
- Издательство:Питер
- Жанр:
- Год:2019
- ISBN:978-5-4461-0950-0
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Распределенные системы. Паттерны проектирования: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Распределенные системы. Паттерны проектирования»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Распределенные системы. Паттерны проектирования — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Распределенные системы. Паттерны проектирования», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
новится равен (R1, Version1) . Теперь при получении запроса уточняется не только текущий владелец, но и версия ресурса. Запрос отклоняется при любом несовпадении. Так мы «подла-тали» данный пример.
Часть III
Пат терны
проектирования систем пакетных вычислений В предыдущей части рассматривались паттерны проектирования надежных, постоянно работающих приложений. В этой части описываются паттерны проектирования систем пакетной об-работки. В отличие от постоянно работающих приложений пакетные процессы обычно работают в течение небольшого промежутка времени. Примерами процессов пакетной обработ-ки могут служить следующие процессы: генерация сводки по данным пользовательской телеметрии, анализ данных продаж для ежедневной или еженедельной отчетности. Пакетные процессы характеризуются быстрой обработкой боль-шого объема данных с максимально возможным применением параллелизма. Самый известный паттерн проектирования рас-пределенных систем — MapReduce — уже успел стать отдель-ным самостоятельным направлением. Есть, однако, и другие паттерны, полезные для пакетной обработки. Они рассматри-ваются в последующих главах.
10 Системы на основе очередей задачПростейшая форма пакетной обработки — очередь задач . В си-стеме с очередью задач есть набор задач, которые должны быть выполнены. Каждая задача полностью независима от остальных и может быть обработана без всяких взаимодей-ствий с ними. В общем случае цель системы с очередью за-дач — обеспечить выполнение каждого этапа работы в течение заданного промежутка времени. Количество рабочих потоков увеличивается либо уменьшается сообразно изменению на-грузки. Схема обобщенной очереди задач представлена на рис. 10.1.
Система на основе обобщенной очереди задач
Очередь задач — идеальный пример, демонстрирующий всю мощь паттернов проектирования распределенных систем. Боль-шая часть логики работы очереди задач никак не зависит от 174Часть III. Паттерны проектирования систем пакетных вычислений
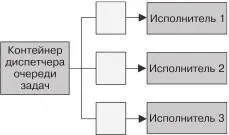


Рис. 10.1. Обобщенная очередь задач
рода выполняемой работы. Во многих случаях то же касается и доставки самих задач. Проиллюстрируем данное утверждение с помощью очереди задач, изображенной на рис. 10.1. Посмо-трев на нее еще раз, определите, какие ее функции могут быть предоставлены совместно используемым набором контейнеров . Становится очевидным, что большая часть реализации контей-неризованной очереди задач может использоваться широким спектром пользователей.
Построение очереди задач на основе контейнеров требует со-гласования интерфейсов между библиотечными контейнерами и контейнерами с пользовательской логикой. В рамках контей-неризованной очереди задач выделяется два интерфейса: ин-терфейс контейнера-источника, предоставляющего поток задач, требующих обработки, и интерфейс контейнера-исполнителя, который знает, как их обрабатывать.
Интерфейс контейнера-источника Любая очередь задач функционирует на основе набора задач, требующих обработки. В зависимости от конкретного при-ложения, реализованного на базе очереди задач, существу-ет множество источников задач, в нее попадающих. Но после получения набора задач схема работы очереди оказывается Глава 10. Системы на основе очередей задач 175
довольно простой. Следовательно, мы можем отделить специ-фичную для приложения логику работы источника задач от обобщенной схемы обработки очереди задач. Вспомнив ранее рассмотренные паттерны групп контейнеров, здесь можно раз-
глядеть реализацию паттерна Ambassador. Контейнер обобщен-ной очереди задач является главным контейнером приложения, а специфичный для приложения контейнер-источник является послом, транслирующим запросы контейнера-диспетчера оче-
реди конкретным исполнителям задач. Данная группа контей-неров изображена на рис. 10.2.
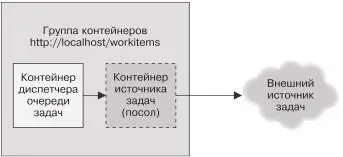
Рис. 10.2. Группа контейнеров, реализующая очередь задачК слову, хотя контейнер-посол специфичен для приложения (что очевидно), существует также ряд обобщенных реализа-ций API источника задач. Например, источником может слу-жить список фотографий, находящихся в некотором облачном хранилище, набор файлов на сетевом диске или даже очередь в системах, работающих по принципу «публикация/подпи-ска», таких как Kafka или Redis. Несмотря на то что пользо-ватели могут выбирать наиболее подходящие под свою задачу контейнеры-послы, им следует использовать обобщенную «библиотечную» реализацию самого контейнера. Так будет минимизирован объем работы и максимизировано повторное использование кода.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Распределенные системы. Паттерны проектирования»
Представляем Вашему вниманию похожие книги на «Распределенные системы. Паттерны проектирования» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Распределенные системы. Паттерны проектирования» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.