Б Бёрнс - Распределенные системы. Паттерны проектирования
Здесь есть возможность читать онлайн «Б Бёрнс - Распределенные системы. Паттерны проектирования» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Год выпуска: 2019, ISBN: 2019, Издательство: Питер, Жанр: Прочая околокомпьтерная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Распределенные системы. Паттерны проектирования
- Автор:
- Издательство:Питер
- Жанр:
- Год:2019
- ISBN:978-5-4461-0950-0
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Распределенные системы. Паттерны проектирования: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Распределенные системы. Паттерны проектирования»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Распределенные системы. Паттерны проектирования — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Распределенные системы. Паттерны проектирования», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
7 Паттерн Scatter/GatherДо сих пор мы изучали реплицированные системы, которые масштабируются по количеству обрабатываемых в секунду запросов (реплицированные сервисы без внутреннего состоя-
ния) либо по объему обрабатываемых данных (шардирован-ные данные). В этой главе описывается паттерн Scatter/Gather , в котором репликация используется для масштабирования по времени. В частности, паттерн Scatter/Gather позволяет добить-
ся параллелизма в обработке запросов, за счет чего вы сможете обслуживать их намного быстрее, чем при последовательной обработке.
Подобно паттернам реплицированных и шардированных си-стем, паттерн Scatter/Gather — древовидный паттерн, в котором корневой узел распределяет запросы, а терминальные узлы их обрабатывают. Однако, в отличие от реплицированных и шар-
дированных систем, запросы в Scatter/Gather-системах рас-пределяются между всеми репликами сервиса. Каждая реплика делает небольшую часть работы и возвращает результат кор-Глава 7. Паттерн Scatter/Gather 123
невому узлу. Корневой узел затем собирает частичные ответы в один общий ответ, который и возвращается клиенту. Паттерн Scatter/Gather схематически изображен на рис. 7.1.
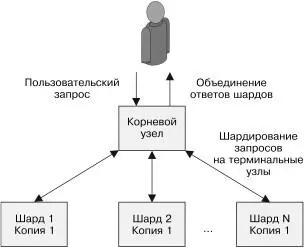
Рис. 7.1. Паттерн Scatter/Gather
Он весьма полезен, если обработка запроса подразумевает большое количество независимых действий. Паттерн Scatter/ Gather может рассматриваться как шардирование вычислений, необходимых для обработки запроса, в противовес шардирова-нию данных (шардирование данных может быть частью этого процесса).
Scatter/Gather с распределением нагрузки корневым узлом
В простейшем варианте паттерна Scatter/Gather все терми-нальные узлы идентичны, а работа распределяется между ними для ускорения обработки запроса. Этот паттерн напоминает 124Часть II. Паттерны проектирования обслуживающих систем
решение «чрезвычайно параллельной» задачи. Задачу можно разбить на множество мелких фрагментов, результаты решения которых можно склеить, чтобы получить полный результат. Разберем его принцип работы на конкретном примере. Пред-ставьте, что вам нужно обслужить запрос R , который на одном ядре выполняется за одну минуту и выдает ответ А. При созда-нии многопоточного приложения мы можем распараллелить обработку запроса на несколько ядер. На 30-ядерном процес-соре (обычно ядер 32, но для ровного счета возьмем 30) время обработки запроса снижается до 2 секунд (60 секунд машинного времени, разделенные на 30 потоков, дают 2 секунды). Но даже 2 секунды — это достаточно долго. Достижение полного парал-лелизма в рамках одного процесса практически невозможно, по-скольку пропускная способность памяти, сетевого подключения или диска становится узким местом. Вместо распараллеливания приложения на несколько ядер одной машины можно исполь-зовать паттерн Scatter/Gather, чтобы распараллелить запросы на несколько процессов, работающих на нескольких машинах. Таким образом, мы можем сократить среднее время обработки запросов, поскольку нас перестает ограничивать количество ядер процессора на одной машине.
Узким местом остается процессор, поскольку пропускная спо-собность памяти, сетевого интерфейса и жесткого диска рас-пределена на несколько машин. Кроме того, поскольку каждая машина в дереве Scatter/Gather способна обработать все за-просы, корневой узел дерева может динамически распределять нагрузку между узлами в зависимости от времени их реакции. Если по какой-то причине некоторый терминальный узел от-вечает медленнее остальных (например, на его ресурсы посягает жадный процесс-сосед), то корневой узел может динамически перераспределить нагрузку, чтобы обеспечить необходимую скорость реакции.
Глава 7. Паттерн Scatter/Gather 125
Практикум. Распределенный поиск в документах
Рассмотрим паттерн Scatter/Gather в действии на примере задачи поиска всех документов, содержащих слова «кот» и «собака», в большой базе документов. Можно открывать все документы подряд и искать в них соответствия образцу поиска, затем возвра-щать пользователю набор документов, в которых есть оба слова. Как вы можете себе представить, этот процесс довольно дли-телен, поскольку для каждого запроса необходимо открывать и считывать большое количество файлов. Чтобы ускорить об-работку, документы можно проиндексировать . Индекс, по сути, представляет собой ассоциативный массив, ключами в котором выступают отдельные слова, а значениями — списки докумен-тов, содержащих данное слово.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Распределенные системы. Паттерны проектирования»
Представляем Вашему вниманию похожие книги на «Распределенные системы. Паттерны проектирования» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Распределенные системы. Паттерны проектирования» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.