Андрей Робачевский - Операционная система UNIX
Здесь есть возможность читать онлайн «Андрей Робачевский - Операционная система UNIX» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Санкт-Петербург, Год выпуска: 1997, ISBN: 1997, Издательство: BHV - Санкт-Петербург, Жанр: ОС и Сети, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Операционная система UNIX
- Автор:
- Издательство:BHV - Санкт-Петербург
- Жанр:
- Год:1997
- Город:Санкт-Петербург
- ISBN:5-7791-0057-8
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Операционная система UNIX: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Операционная система UNIX»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
В книге рассматриваются: архитектура ядра UNIX (подсистемы ввода/вывода, управления памятью и процессами, а также файловая подсистема), программный интерфейс UNIX (системные вызовы и основные библиотечные функции), пользовательская среда (командный интерпретатор shell, основные команды и утилиты) и сетевая поддержка в UNIX (протоколов семейства TCP/IP, архитектура сетевой подсистемы, программные интерфейсы сокетов и TLI).
Для широкого круга пользователей
Операционная система UNIX — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Операционная система UNIX», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Относительно низкая производительность связана с размещением компонентов файловой системы на диске. Метаданные файлов располагаются в начале файловой системы, а далее следуют блоки хранения данных. При работе с файлом, происходит обращение как к его метаданным, так и к дисковым блокам, содержащим его данные. Поскольку эти структуры данных могут быть значительно разнесены в дисковом пространстве, необходимость постоянного перемещения головки диска увеличивает время доступа и, как следствие, уменьшает производительность файловой системы в целом. К этому же эффекту приводит фрагментация файловой системы, поскольку отдельные блоки файла оказываются разбросанными по всему разделу диска.
Использование дискового пространства также не оптимально. Для увеличения производительности файловой системы более предпочтительным является использование блоков больших размеров. Это позволяет считывать большее количество данных за одну операцию ввода/вывода. Так, например, в UNIX SVR2 размер блока составлял 512 байтов, а в SVR3 — уже 1024 байтов. Однако поскольку блок может использоваться только одним файлом, увеличение размера блока приводит к увеличению неиспользуемого дискового пространства за счет частичного заполнения последнего блока файла. В среднем для каждого файла теряется половина блока.
Массив inode имеет фиксированный размер, задаваемый при создании файловой системы. Этот размер накладывает ограничение на максимальное число файлов, которые могут существовать в файловой системе. Расположение границы между метаданными файлов и их данными (блоками хранения данных) может оказаться неоптимальным, приводящим либо к нехватке inode, если файловая система хранит файлы небольшого размера, либо к нехватке дисковых блоков для хранения файлов большого размера. Поскольку динамически изменить эту границу невозможно, всегда останется неиспользованное дисковое пространство либо в массиве inode, либо в блоках хранения данных.
Наконец, ограничения, накладываемые на длину имени файла (14 символов) и общее максимальное число inode (65 535), также являются слишком жесткими.
Все эти недостатки привели к разработке новой архитектуры файловой системы, которая появилась в версии 4.2BSD UNIX под названием Berkeley Fast File System, или FSS.
Файловая система BSD UNIX
В версии 4.3BSD UNIX были внесены существенные улучшения в архитектуру файловой системы, повышающие как ее производительность, так и надежность. Новая файловая система получила название Berkeley Fast File System (FFS).
Файловая система FFS, обладая полной функциональностью системы s5fs, использует те же структуры данных ядра. Основные изменения затронули расположение файловой системы на диске, дисковые структуры данных и алгоритмы размещения свободных блоков.
Как и в случае файловой системы s5fs, суперблок содержит общее описание файловой системы и располагается в начале раздела. Однако в суперблоке не хранятся данные о свободном пространстве файловой системы, такие как массив свободных блоков и inode. Поэтому данные суперблока остаются неизменными на протяжении всего времени существования файловой системы. Поскольку данные суперблока жизненно важны для работы всей файловой системы, он дублируется для повышения надежности.
Организация файловой системы предусматривает логическое деление дискового раздела на одну или несколько групп цилиндров (cylinder group). Группа цилиндров представляет собой несколько последовательных дисковых цилиндров. Каждая группа цилиндров содержит управляющую информацию, включающую резервную копию суперблока, массив inode, данные о свободных блоках и итоговую информацию об использовании дисковых блоков в группе (рис. 4.4).
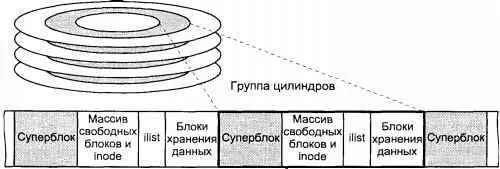
Рис. 4.4. Структура файловой системы FFS
Для каждой группы цилиндров при создании файловой системы выделяется место под определенное количество inode. При этом обычно на каждые 2 Кбайт блоков хранения данных создается один inode. Поскольку размеры группы цилиндров и массива inode фиксированы, в файловой системе BSD UNIX присутствуют ограничения, аналогичные s5fs.
Идея такой структуры файловой системы заключается в создании кластеров inode, распределенных по всему разделу, вместо того, чтобы группировать все inode в начале. Тем самым уменьшается время доступа к данным конкретного файла, поскольку блоки данных располагаются ближе к адресующем их inode. Такой подход также повышает надежность файловой системы, уменьшая вероятность потери всех индексных дескрипторов в результате сбоя.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Операционная система UNIX»
Представляем Вашему вниманию похожие книги на «Операционная система UNIX» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.










Обсуждение, отзывы о книге «Операционная система UNIX» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.