Джин Ким - Руководство по DevOps
Здесь есть возможность читать онлайн «Джин Ким - Руководство по DevOps» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2018, ISBN: 2018, Издательство: Манн, Иванов и Фербер, Жанр: Интернет, Базы данных, Прочая околокомпьтерная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Руководство по DevOps
- Автор:
- Издательство:Манн, Иванов и Фербер
- Жанр:
- Год:2018
- Город:Москва
- ISBN:9785001007500
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Руководство по DevOps: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Руководство по DevOps»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Руководство по DevOps — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Руководство по DevOps», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Другими словами, когда плотность распределения наблюдений описывается не показанной выше колоколообразной кривой, привычные свойства стандартных отклонений использовать нельзя. Например, представим, что мы наблюдаем за количеством скачиваний файла с нашего сайта в минуту. Нам нужно определить периоды, когда у нас необычно высокое число скачиваний. Пусть это число будет больше, чем три стандартных отклонения от среднего. Тогда мы сможем заранее увеличивать мощность или пропускную способность.
Рис. 30 показывает число одновременных скачиваний в минуту. Когда участок линии сверху графика выделен черным цветом, количество скачиваний в заданный период (иногда называемый «скользящим окном») превышает заданную величину. В противном случае линия окрашена в серый цвет.
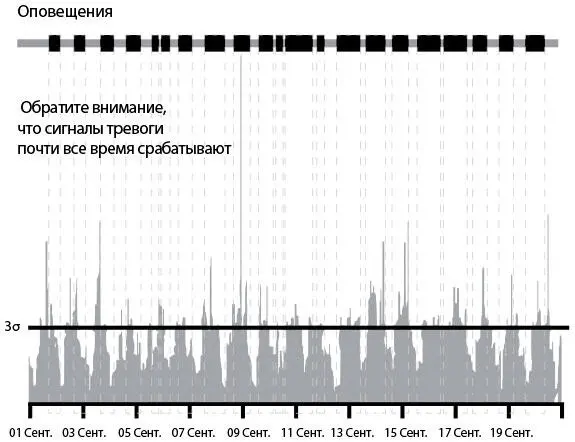
Рис. 30. Число загрузок в минуту: чрезмерное оповещение о проблемах при использовании правила трех стандартных отклонений (источник: Туфик Бубе, “Simple math for anomaly detection”)
График наглядно показывает очевидную проблему: оповещения идут практически непрерывным потоком. Это происходит потому, что почти в любой период у нас есть моменты, когда число скачиваний превышает порог в три стандартных отклонения.
Чтобы доказать это, построим гистограмму (рис. 31). На ней показана частота скачиваний в минуту. Форма гистограммы отличается от классической куполообразной кривой. Вместо этого распределение явно скошено к левому краю. Это говорит нам о том, что б о льшую часть времени у нас малое число скачиваний в минуту, но при этом число скачиваний очень часто превышает предел в три стандартных отклонения.
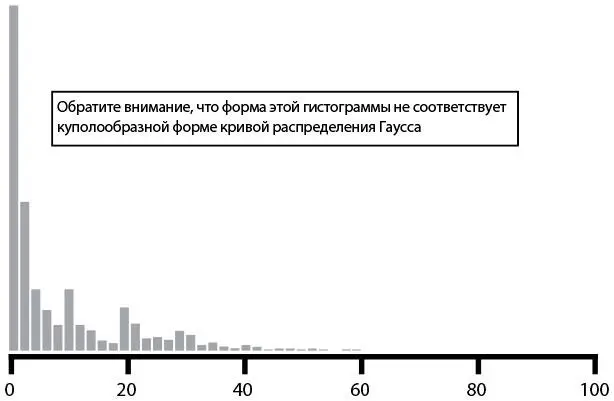
Рис. 31. Число скачиваний в минуту: гистограмма данных, имеющих негауссово распределение (источник: Туфик Бубе, “Simple math for anomaly detection”)
У многих реальных наборов данных распределение не нормально. Николь Форсгрен объясняет: «В эксплуатации у многих наших комплектов данных так называемое распределение хи-квадрат. Использование стандартных отклонений для них не только приводит к чрезмерному или недостаточному количеству оповещений, но и просто выдает бессмысленные результаты». Далее, Николь отмечает: «Когда вы считаете число одновременных скачиваний, которое на три стандартных отклонения меньше среднего, вы получаете отрицательное число. А это явно бессмысленно».
Чрезмерное количество оповещений приводит к тому, что инженеров эксплуатации часто будят среди ночи и долго держат на ногах, даже когда они мало что могут сделать. Проблема недостаточного оповещения о проблемах также весьма значительна. Например, предположим, что мы наблюдаем число завершенных транзакций и из-за отказа какого-то компонента количество транзакций в середине дня внезапно падает на 50 %. Если эта величина находится в пределах трех стандартных отклонений от среднего, никакого сигнала тревоги подано не будет, а значит, наши клиенты обнаружат эту проблему раньше, чем мы. Если дойдет до этого, решить проблему будет гораздо сложнее.
К счастью, для выявления аномалий в наборах данных, имеющих не нормальное распределение, тоже есть специальные методики. О них мы расскажем ниже.
Еще один инструмент, разработанный в Netflix для улучшения качества услуг, Scryer, борется с некоторыми недостатками сервиса Auto Scaling [119]компании Amazon (далее — AAS), который динамически увеличивает и уменьшает количество вычислительных серверов AWS [120]в зависимости от данных по нагрузке. Система Scryer на основе прошлого поведения пользователя предсказывает, что именно ему может потребоваться, и предоставляет нужные ресурсы.
Scryer решил три проблемы AAS. Первая заключалась в обработке резких пиков нагрузки. Поскольку время включения инстансов AWS составляет от 10 до 45 минут, дополнительные вычислительные мощности часто загружались слишком поздно, чтобы справиться с пиковыми нагрузками. Суть второй проблемы в следующем: после сбоев быстрый спад пользовательского спроса приводил к тому, что AAS отключал слишком много вычислительных мощностей и потом не справлялся с последующим увеличением нагрузки. Третья проблема — AAS не учитывал в расчетах известные ему паттерны использования трафика.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Руководство по DevOps»
Представляем Вашему вниманию похожие книги на «Руководство по DevOps» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Руководство по DevOps» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.