Николай Мациевский - Разгони свой сайт
Здесь есть возможность читать онлайн «Николай Мациевский - Разгони свой сайт» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: Интернет, Программирование, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Разгони свой сайт
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Разгони свой сайт: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Разгони свой сайт»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Разгони свой сайт — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Разгони свой сайт», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Формализация модели
Для начала нужно было каким-либо образом установить издержки на само архивирование. Схематично эти накладные расходы можно представить примерно в следующем виде:
gzip = чтение/запись на диск + инициализация библиотеки + создание архива
Предполагается, что первые две составляющие не зависят от размера файла (в исследовании участвовали файлы от 500 байтов до 128 Кб), а являются более-менее постоянными (по сравнению с последним слагаемым). Однако, как оказалось, работы с файловой системой зависят от размера. Об этом чуть подробнее рассказывается ниже.
Естественно, что процессорные ресурсы, уходящие на «создание архива», должны быть примерно линейными от размера файла (линейное приближение вносит погрешность не больше, чем остальные предположения), поэтому результирующая формула примет примерно такой вид:
gzip = FS + LI + K*size
Здесь FS— издержки на файловую систему, LI— издержки на инициализацию библиотеки и любые другие постоянные издержки, зависящие от реализации gzip, а K— коэффициент пропорциональности размера файла увеличению времени его архивирования.
Набор тестов
Итак, для проверки гипотезы и установления истинных коэффициентов нам потребуется 2 набора тестов:
Тесты на сжатие: для набора пар значений «size — gzip»
Тесты на запись: для набора пар значений «size — FS»
Почему именно 2 — а как же издержки на инициализацию архивирования, спросите вы? Потому что в таком случае у нас получится система (не)линейных уравнений, а найти из нее 2 неизвестных (коэффициент пропорциональности и статические издержки) не представляется сложным. Решать переопределенную систему и рассчитывать лишний раз точную погрешность измерения не требуется: статистическими методами погрешность и так сводится к минимуму.
Для тестирования был взят обычный HTML-файл (чтобы условия максимально соответствовали реальным). Затем из него были вырезаны первые 500, 1000 ... 128000 байтов. Все получившиеся файлы на сервере сначала в цикле архивировались нужное число раз, затем открывались и копировались на файловую систему — с помощью встроенных средств ОС Linux (cat, gzip), чтобы не добавлять дополнительных издержек какого-либо «внешнего» языка программирования.
Результаты тестирования
Для сжатия был получен следующий график. Хорошо заметно, что для небольших файлов основные издержки вносятся работой с файловой системой, а не архивированием. Здесь и далее все времена указаны в миллисекундах. Проводились серии тестов по 10000 итераций.
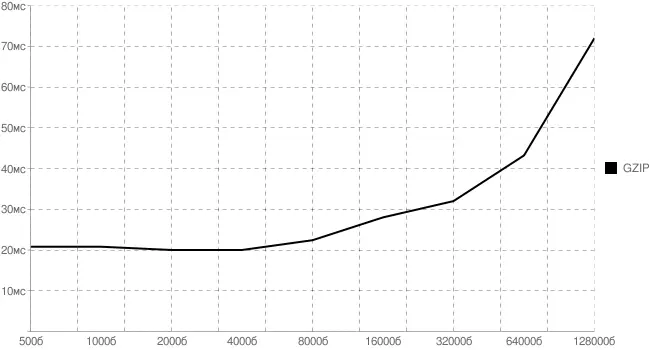
Рис. 2.1 . График издержек на gzip-сжатие от размера файла
Теперь добавим исследования по работе с файловой системой, вычтем их из общих издержек и получим следующую картину.

Рис. 2.2 . График издержек на gzip-сжатие и работу с файловой системой
Издержки на открытие, запись, закрытие файла зависят в некоторой степени от размера, однако это не мешает нам построить модельную зависимость вычислительной нагрузки от размера файла (предполагая, что в данном диапазоне она линейна). В результате получим следующее (рис. 2.3).
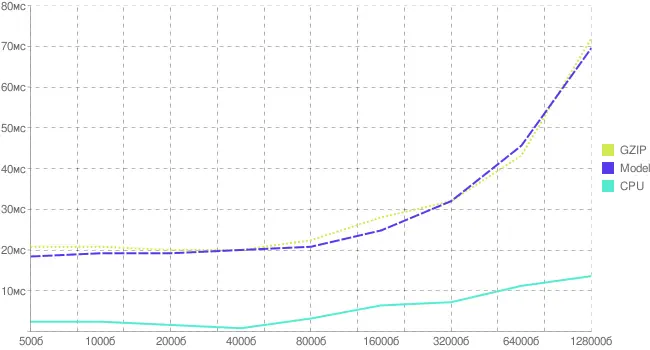
Рис. 2.3 . График реальных и модельных издержек на gzip-сжатие
Пара слов о файловой системе
Вопрос: зачем нужны дополнительные тесты на производительность файловой системы, ведь уже есть характерное время, уходящее на gzip-сжатие определенных размеров файлов?
Ответ: во-первых, любой веб-сервер и так берет файл из файловой системы и архивирует уже в памяти, а потом пишет в сокет. Это время уже учтено при установлении соединения с сервером до получения первого байта. Нам лишь нужно понять, насколько оно увеличится, если сервер произведет еще некоторые операции с данными в оперативной памяти.
Во-вторых, не все серверы читают прямо с диска. У высоконагруженных систем и прокси-серверов (например, 0W, squid, nginx, thttpd) данные могут храниться прямо в оперативной памяти, поэтому время доступа к ним существенно меньше, чем к файловой системе. Соответственно, его и нужно исключить из полученных результатов.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Разгони свой сайт»
Представляем Вашему вниманию похожие книги на «Разгони свой сайт» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Разгони свой сайт» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.