Олег Деревенец - Песни о Паскале
Здесь есть возможность читать онлайн «Олег Деревенец - Песни о Паскале» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: Базы данных, tbg_computers, network_literature, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Песни о Паскале
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Песни о Паскале: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Песни о Паскале»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Песни о Паскале — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Песни о Паскале», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
var sym : char;
...
Read(InFile, sym); { чтение одного символа }
А фамилию S склеим из отдельных букв:
S:= S + sym;
Разумеется, что здесь нужен цикл, условием выхода из которого будет либо достижение первого пробела, либо достижение конца строки. В этом и состоит основная идея алгоритма, показанного на рис. 71.
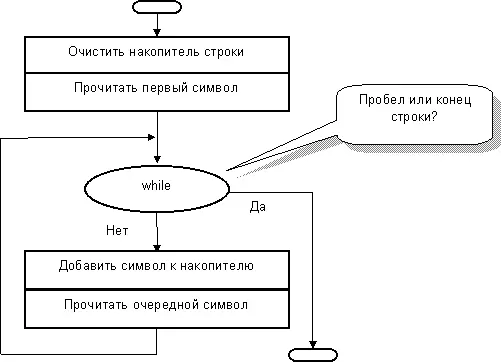
Людям свойственно ошибаться, – даже учителям! В строках журнала (а это текстовый файл) могут оказаться лишние пробелы – как между оценками, так и в начале строки, перед фамилией. И что тогда? – проверьте на практике. При чтении чисел процедура Read «не заметит» лишних пробелов, – она достаточно «умна». Другое дело – показанная выше блок-схема: если перед фамилией обнаружится пробел, то чтение слова завершится досрочно. Стало быть, для правильного чтения фамилии надо пропустить стоящие перед нею пробелы (если они есть). Это улучшение слегка усложнит блок-схему (рис. 72).
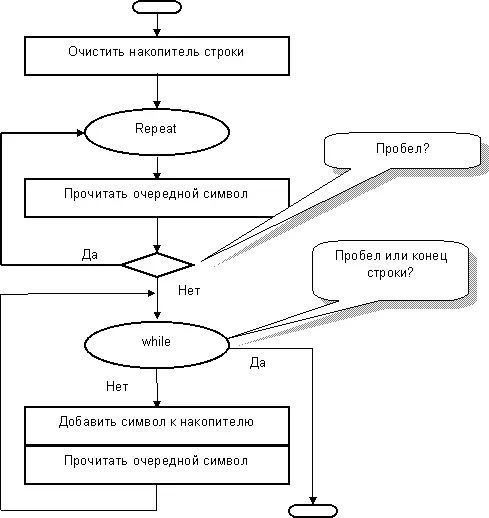
В основу новой версии программы «P_31_1» положим программу «P_30_1». Вам следует, прежде всего, открыть её и сохранить под новым именем. Готово? Тогда приступаем к правке.
Начнем с главной программы, где надо изменить имена входных и выходных файлов (чтобы не путать с похожими файлами предыдущей версии).
Assign(InFile, 'Journal2.in' ); Reset(InFile);
Assign(OutFile, 'Journal2.out' ); Rewrite(OutFile);
Позаботьтесь о том, чтобы файл «Journal2.in» был похож на настоящий классный журнал с фамилиями, как о нём сказано в начале 30-й главы.
Второе изменение внесем в процедуру обработки строки HandleString. Здесь объявим ещё одну переменную строкового типа, назовем её Fam, она будет вмещать фамилию ученика.
Fam:= ReadFam ; { читаем фамилию }
Разумеется, оператор печати строки тоже будет изменен.
Writeln(OutFile, Counter:3, Fam:18 , Cnt:8, Sum:14, Rating:11:1);
Осталось выяснить, что такое ReadFam? Это функция чтения фамилии, которую мы напишем по рассмотренному чуть выше алгоритму (рис. 72). Мой вариант функции таков.
function ReadFam: string;
var sym: char; { очередной символ }
S : string; { накопитель строки }
begin
S:=''; { очистка накопителя строки }
{ чтение символов до первой буквы }
repeat Read(InFile, sym); until Ord(sym)>32 ;
{ чтение последующих символов }
repeat
s:= s+sym;
if Eoln(InFile) then Break;
Read(InFile, sym);
until not ((Ord(sym)>32));
ReadFam:= S; { возвращаемый результат }
end;
Обратите внимание на сравнение введенного символа с пробелом. Это сравнение можно было бы записать так:
sym <> ’ ’
Но пробел в кавычках трудно разглядеть. Лучше сравнивать код символа с кодом пробела (который равен 32), что и сделано внутри функции.
Теперь все готово, запустите программу. Что оказалось в выходном файле «Journal2.out»? Наверное, вот это.
Номер Фамилия Количество Сумма Средний
ученика оценок баллов балл
1 Акулова 3 12 4.0
2 Быков 4 20 5.0
3 Волков 4 18 4.5
4 Галкина 3 10 3.3
5 Крокодилкин 2 7 3.5
Если не считать кривых колонок, неплохо. Кривизну даёт разная длина фамилий учеников. Можно выровнять колонки, вычисляя спецификатор ширины в зависимости от длины фамилии. Или поступить иначе, – дополнить фамилии до одинаковой длины пробелами справа, например:
while Length(Fam) < 12 do Fam:= Fam + Char(32);
Этот оператор уместен после чтения фамилии. Окончательный вариант программы со всеми дополнениями и уточнениями представлен ниже.
{ P_31_1 – Обработка классного журнала, второй этап }
var InFile, OutFile : text; { входной и выходной файлы }
Counter: integer; { счетчик строк в файле }
{----- Функция чтения фамилии -----}
function ReadFam: string;
var sym: char;
S : string;
begin
s:=''; { очистка накопителя строки }
Интервал:
Закладка:
Похожие книги на «Песни о Паскале»
Представляем Вашему вниманию похожие книги на «Песни о Паскале» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Песни о Паскале» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.