Олег Деревенец - Песни о Паскале
Здесь есть возможность читать онлайн «Олег Деревенец - Песни о Паскале» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: Базы данных, tbg_computers, network_literature, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Песни о Паскале
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Песни о Паскале: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Песни о Паскале»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Песни о Паскале — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Песни о Паскале», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Внутри цикла находим непривычный оператор присваивания.
FindNumber:= (N=aNumber); { true, если номер нашелся }
Левая его часть – это идентификатор функции, а правая (в скобках) – оператор сравнения двух чисел. Оператор сравнения дает булев результат, равный TRUE, если числа совпадают. Скобки в правой части здесь не нужны, но я поставил их для наглядности. Приведенный выше оператор можно было бы заменить таким.
if N=aNumber
then FindNumber:= true
else FindNumber:= false;
Но, согласитесь, первый вариант наглядней и короче.
Итак, прежде чем двинуться дальше, не поленитесь проверить эту программу.
Теперь слегка изменим расположение чисел в файле «Police.txt». Вместо одного числа в строке, напечатайте в каждой по нескольку чисел, разделив их одним или несколькими пробелами, например:
123 234 325
223 240
845 431 205
Подобное расположение данных вполне обычно, взгляните хотя бы в классный журнал, где в одной строке проставлен ряд оценок. Мы, программисты, должны извлекать данные даже из таких файлов.
Переключитесь в окно нашей базы данных «Police.txt» и внесите необходимые изменения. Сохранить файл не забыли? Теперь запустите программу и проверьте её на номерах из этого файла. При должном внимании вы обнаружите, что программа правильно находит только числа, начинающие строку, например 123, 223 и 845. Все последующие номера в строке программа не замечает, хотя и аварийных сообщений не выдает. В чем же дело?
Причина – в процедуре Readln. До сих пор мы пользовались ею для чтения строк и горя не знали. Но числа – иное дело. Приглашаю вас мысленно проследить за позицией чтения в ходе просмотра нашей БД (рис. 66). Невидимые признаки конца строки обозначены на рисунке условными символами Eoln (это пара символов с кодами 13 и 10).
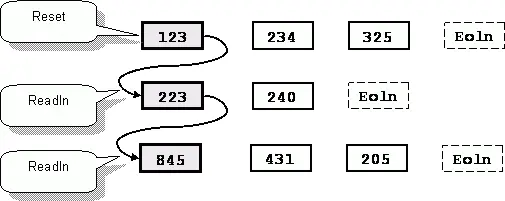
После того, как Reset установит позицию чтения в начало файла, процедура Readln прочитает первое число. Чтение идет цифра за цифрой, пока не встретится любой символ, отличный от неё, например, пробел или конец строки. Проглотив таким образом первое число, процедура Readln продвинет позицию чтения в начало следующей строки, пропуская при этом все, что расположено до конца текущей. Вот в чем дело! Не зря к названию процедуры прилепился суффикс «LN» (сокращенное от Line – «строка»). Источник проблемы ясен: процедура Readln не подходит для чтения нескольких чисел в строке. Где же выход?
Спокойно, друзья, в Паскале заготовлено все! Познакомьтесь с процедурой Read (без суффикса), которая почти не отличается от своей «сестренки» – принимает те же параметры и читает те же данные. Но при этом самовольно не продвигает позицию чтения в начало следующей строки. А нам того и нужно! Продвижение позиции чтения процедурой Read показано на рис. 67.
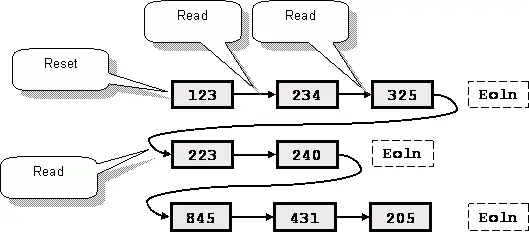
После чтения каждого числа позиция продвигается за это число и остается там. Следующий вызов процедуры прочитает очередное число в этой же строке и так далее, пока не будет достигнут конец строки. А потом? Потом позиция сдвинется в начало следующей строки, и чтение продолжится тем же чередом до конца файла.
Итак, решение найдено, и теперь для правильной работы программы надо лишь удалить суффикс в имени процедуры, то есть заменить вызов
Readln(aFile, N);
на вызов
Read(aFile, N);
Внесите это исправление в программу, сохраните её под именем «P_29_2» и проверьте, работает ли она.
Предвижу законный вопрос: к чему в языке две похожие процедуры, нельзя ли обойтись только Read? Нет, нельзя, – процедура Readln незаменима при построчной обработке файлов, и очень скоро вы в этом убедитесь.
• База данных – это организованное хранилище информации, приспособленное для быстрого её поиска. Простейшую базу данных можно создать редактором текста.
• Перед поиском данных в текстовом файле, надо установить позицию чтения в начало файла процедурой Reset.
• Процедура Readln после чтения затребованных данных продвигает позицию чтения в начало следующей строки. При этом все непрочитанные данные в текущей строке пропускаются.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Песни о Паскале»
Представляем Вашему вниманию похожие книги на «Песни о Паскале» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Песни о Паскале» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.