Коллектив Авторов - Базы данных - конспект лекций
Здесь есть возможность читать онлайн «Коллектив Авторов - Базы данных - конспект лекций» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2007, ISBN: 2007, Издательство: Array Конспекты, шпаргалки, учебники «ЭКСМО», Жанр: Базы данных, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Базы данных: конспект лекций
- Автор:
- Издательство:Array Конспекты, шпаргалки, учебники «ЭКСМО»
- Жанр:
- Год:2007
- Город:Москва
- ISBN:978-5-699-23778-4
- Рейтинг книги:4.5 / 5. Голосов: 2
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Базы данных: конспект лекций: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Базы данных: конспект лекций»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Лаконичное и четкое изложение материала, продуманный отбор необходимых тем позволяют быстро и качественно подготовиться к семинарам, зачетам и экзаменам по данному предмету.
Базы данных: конспект лекций — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Базы данных: конспект лекций», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
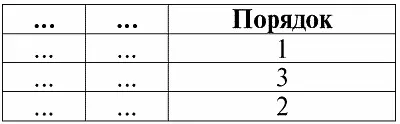
4. В таблице, представляющей отношение, не должно быть строк-дубликатов. Если же в таблице встречаются повторяющиеся строки, это можно легко исправить введением дополнительного столбца, отвечающего за количество дубликатов каждой строки, например:
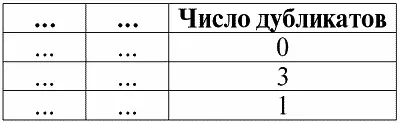
Следующее свойство также является вполне ожидаемым, потому что лежит в основе всех принципов программирования и проектирования реляционных баз данных.
5. Данные во всех столбцах должны быть одного и того же типа. И кроме того они должны быть простого типа.
Поясним, что такое простой и сложный типы данных.
Простой тип данных – это такой тип, значения данных которого не являются составными, т. е. не содержат составных частей. Таким образом, в столбцах таблицы не должны присутствовать ни списки, ни массивы, ни деревья, ни подобные названным составные объекты.
Такие объекты – составной тип данных– в реляционных системах управления базами данных сами представляются в виде самостоятельных таблиц-отношений.
2. Домены и атрибуты
Домены и атрибуты – базовые понятия в теории создания баз данных и управления ими. Поясним, что же это такое.
Формально, домен атрибута(обозначается dom(a)), где а – некий атрибут, определяется как множество допустимых значений одного и того же типа соответствующего атрибута а. Этот тип должен быть простым, т. е:
dom(a) ⊆ {x | type(x) = type(a)};
Атрибут(обозначается а), в свою очередь, определяется как упорядоченная пара, состоящая из имени атрибута name(a) и домена атрибута dom(a), т. е.:
a = (name(a): dom(a));
В этом определении вместо привычного знака «,» (как в стандартных определениях упорядоченных пар) используется «:». Это делается для того, чтобы подчеркнуть ассоциацию домена атрибута и типа данных атрибута.
Приведем несколько примеров различных атрибутов:
а 1= (Курс: {1, 2, 3, 4, 5});
а 2= (МассаКг: {x | type(x) = real, x 0});
а 3= (ДлинаСм: {x | type(x) = real, x 0});
Заметим, что у атрибутов а 2и а 3домены формально совпадают. Но семантическое значение этих атрибутов различно, ведь сравнивать значения массы и длины бессмысленно. Поэтому домен атрибута ассоциируется не только с типом допустимых значений, но и семантическим значением.
В табличной форме представления отношений атрибут отображается как заголовок столбца таблицы, и при этом домен атрибута не указывается, но подразумевается. Это выглядит следующим образом:
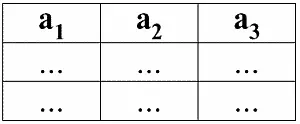
Нетрудно заметить, что здесь каждый из заголовков a 1, a 2, a 3столбцов таблицы, представляющей какое-то отношение, является отдельным атрибутом.
3. Схемы отношений. Именованные значения кортежей
В теории и практике СУБД понятия схемы отношения и именованного значения кортежа на атрибуте являются базовыми. Приведем их.
Схема отношения(обозначается S) определяется как конечное множество атрибутов с уникальными именами, т. е.:
S = {a | a ∈ S};
В каждой таблице, представляющей отношение, все заголовки столбцов (все атрибуты) объединяются в схему этого отношения.
Количество атрибутов в схеме отношений определяет степеньэтого отношенияи обозначается как мощность множества: | S|.
Схема отношений может ассоциироваться с именем схемы отношений.
В табличной форме представления отношений, как нетрудно заметить, схема отношения – это не что иное, как строка заголовков столбцов.

S = {a 1, a 2, a 3, a 4} – схема отношений этой таблицы.
Имя отношения изображается как схематический заголовок таблицы.
В текстовой же форме представления схема отношений может быть представлена как именованный список имен атрибутов, например:
Студенты (№ зачетной книжки, Фамилия, Имя, Отчество, Дата рождения).
Здесь, как и в табличной форме представления, домены атрибутов не указываются, но подразумеваются.
Из определения следует, что схема отношения может быть и пустой (S = ∅). Правда, возможно это только в теории, так как на практике система управления базами данных никогда не допустит создания пустой схемы отношения.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Базы данных: конспект лекций»
Представляем Вашему вниманию похожие книги на «Базы данных: конспект лекций» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.










Обсуждение, отзывы о книге «Базы данных: конспект лекций» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.