Хелен Борри - Firebird РУКОВОДСТВО РАЗРАБОТЧИКА БАЗ ДАННЫХ
Здесь есть возможность читать онлайн «Хелен Борри - Firebird РУКОВОДСТВО РАЗРАБОТЧИКА БАЗ ДАННЫХ» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Санкт-Петербург, Год выпуска: 2006, ISBN: 2006, Издательство: БХВ-Петербург, Жанр: Базы данных, Программирование, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Firebird РУКОВОДСТВО РАЗРАБОТЧИКА БАЗ ДАННЫХ
- Автор:
- Издательство:БХВ-Петербург
- Жанр:
- Год:2006
- Город:Санкт-Петербург
- ISBN:5-94157-609-9
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Firebird РУКОВОДСТВО РАЗРАБОТЧИКА БАЗ ДАННЫХ: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Firebird РУКОВОДСТВО РАЗРАБОТЧИКА БАЗ ДАННЫХ»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Для разработчиков баз данных
Firebird РУКОВОДСТВО РАЗРАБОТЧИКА БАЗ ДАННЫХ — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Firebird РУКОВОДСТВО РАЗРАБОТЧИКА БАЗ ДАННЫХ», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Вы можете добавить переключатель -system, чтобы включить сведения о системных индексах в отчет.
Чтобы запустить утилиту для базы данных employee и направить ее вывод в текстовый файл с именем gstat.index.txt, выполните следующее:
* в POSIX наберите (все в одной строке):
./gstat -index /opt/firebird/examples/employee.fdb -t CUSTOMER -user SYSDBA -password masterkey
> /opt/firebird/examples/gstat.index.txt
* в Win32 наберите (все в одной строке):
gstat -index
"c:\Program Files\Firebird\Firebird_1_5\examples\employee.fdb" -t CUSTOMER
-user SYSDBA -password masterkey
> "c:\Program Files\Firebird\Firebird_1_5\examples\gstat.index.txt"
! ! !
ПРИМЕЧАНИЕ. Двойные кавычки для пути к базе данных требуются в Windows, если ваш путь содержит пробелы.
. ! .
На рис. 18.3 показано, как отображаются данные индексной страницы.
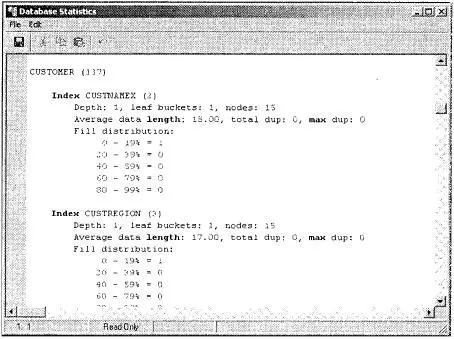
Рис. 18.3. Пример отображения данных индексной страницы
Вначале появляется итоговая информация об индексе. В табл. 18.2 объясняются записи строка за строкой.
Поскольку утилита gstat выполняет свой анализ на уровне файла, она не использует концепции транзакции. Следовательно, статистика по индексам также включает информацию по тем индексам, которые используются в незавершенных транзакциях.
Таблица 18.2. Вывод gstat -i[ndex]
|
Элемент |
Описание |
|
Index |
Имя индекса |
|
Depth |
Количество уровней в странице индексного дерева. Если глубина дерева индексной страницы превышает 3, то доступ к записям через индекс не будет максимально эффективным. Для уменьшения глубины дерева индексной страницы увеличьте размер страницы. Если увеличение размера страницы не уменьшает глубины, снова увеличьте размер страницы |
|
Leaf buckets |
Количество страниц самого низкого уровня (листовых) в дереве индекса. Это страницы, которые содержат указатели на записи. Страницы высокого уровня содержат косвенные связи |
|
Nodes |
Общее количество записей, индексированных в дереве. Должно быть равно количеству индексированных строк в дереве, хотя отчет gstat может включать узлы, которые были удалены, но не вычищены в процессе сборки мусора. Может также включать множество элементов для записей, у которых был изменен индексный ключ |
|
Average data length |
Средняя длина каждого ключа в байтах. Обычно имеет много меньшее значение, чем длина объявленного ключа, потому что выполняется сжатие суффикса и префикса |
|
Total dup |
Общее количество строк дубликатов индекса |
|
Max dup |
Количество дублирующих узлов в "цепочке", имеющих наибольшее количество дубликатов. Всегда будет нулем для уникальных индексов. Если число велико по сравнению с числом в Total dup, то это признак плохой селективности |
|
Average fill |
Это гистограмма с пятью 20-процентными полосами, каждая из которых показывает количество индексных страниц, чей средний процент заполнения находится в указанном диапазоне. Процент заполнения определяется соотношением пространства каждой страницы, содержащей данные. Сумма таких чисел дает общее количество страниц, содержащих индексные данные |
Индекс является древовидной структурой со страницами на одном уровне, ссылающимися на страницы другого уровня и т.д. вплоть до страниц, указывающих на строки данных. Чем больше глубина, тем больше косвенных уровней. Строка Leaf bucket описывает страницы индекса самого низкого уровня, которые указывают на индивидуальные строки.
На рис. 18.4 корневая страница индекса (создаваемая при создании базы данных) хранит указатель для каждого индекса и указатель на другую страницу указателей, которая содержит указатели этого индекса. Такая страница последовательно указывает на страницы, содержащие данные - фактические данные узлов - либо непосредственно (глубина равна 1), либо косвенно (добавляя один уровень для каждого косвенного уровня).
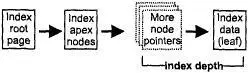
Рис. 18.4. Глубина индекса
Два фактора оказывают влияние на глубину: размеры страницы и ключа. Если глубина больше 3 и размер страницы меньше 8192, то увеличение размера страницы до 8192 или 16 386 должно уменьшить количество косвенных уровней и увеличить скорость.
! ! !
СОВЕТ. Вы можете вычислить приблизительный размер (в страницах) цепочки мах dup на основании статистических данных. Для получения количества узлов на странице разделите узлы (nodes) на количество листьев (leaf buckets). Умножение результата на максимальное количество дублирующих узлов (max dup) дает приблизительное количество страниц.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Firebird РУКОВОДСТВО РАЗРАБОТЧИКА БАЗ ДАННЫХ»
Представляем Вашему вниманию похожие книги на «Firebird РУКОВОДСТВО РАЗРАБОТЧИКА БАЗ ДАННЫХ» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Firebird РУКОВОДСТВО РАЗРАБОТЧИКА БАЗ ДАННЫХ» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.