Хелен Борри - Firebird РУКОВОДСТВО РАЗРАБОТЧИКА БАЗ ДАННЫХ
Здесь есть возможность читать онлайн «Хелен Борри - Firebird РУКОВОДСТВО РАЗРАБОТЧИКА БАЗ ДАННЫХ» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Санкт-Петербург, Год выпуска: 2006, ISBN: 2006, Издательство: БХВ-Петербург, Жанр: Базы данных, Программирование, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Firebird РУКОВОДСТВО РАЗРАБОТЧИКА БАЗ ДАННЫХ
- Автор:
- Издательство:БХВ-Петербург
- Жанр:
- Год:2006
- Город:Санкт-Петербург
- ISBN:5-94157-609-9
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Firebird РУКОВОДСТВО РАЗРАБОТЧИКА БАЗ ДАННЫХ: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Firebird РУКОВОДСТВО РАЗРАБОТЧИКА БАЗ ДАННЫХ»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Для разработчиков баз данных
Firebird РУКОВОДСТВО РАЗРАБОТЧИКА БАЗ ДАННЫХ — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Firebird РУКОВОДСТВО РАЗРАБОТЧИКА БАЗ ДАННЫХ», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
SELECT PRODUCT_ID, UPPER(PRODUCT_NAME) FROM PRODUCT
GROUP BY PRODUCT_ID, UPPER(PRODUCT_NAME)
HAVING COUNT(*) > 1;
! ! !
ПРИМЕЧАНИЕ. Перевод значения столбца в верхний регистр, чтобы сделать поиск не чувствительным к регистру, не является необходимым с точки зрения уникальности данных. Тем не менее, если уникальность была "поломана" вводом ошибочных данных, мы можем отыскать все неправильные записи.
. ! .
Как вы поступите с дубликатами, зависит от того, что они означают в ваших бизнес- правилах, и от количества дубликатов, которые нужно уменьшить. Обычно, храни- мая процедура является наиболее эффективным способом это обработать. Хранимые процедуры подробно обсуждаются в главах 28-30.
Ключевые слова ASC[ENDING] и DESC[ENDING] определяют вертикальный порядок сортировки индекса, ASC задает сортировку индекса от меньшего к большему. Оно является значением по умолчанию и может быть опущено, DESC сортирует значения от большего к меньшему и должно быть указано, если требуется убывающий индекс. Убывающий индекс может быть полезным для запросов, которые отыскивают наибольшие значения (наибольший возраст, самый последний, самый большой и т.д.), а также при упорядоченном поиске или для выходных данных, которые должны быть отсортированы в убывающем порядке.
Следующее определение создает убывающий индекс для таблицы в базе данных employee:
CREATE DESCENDING INDEX DESC_X ON SALAR Y_HISTORY (CHANGE_DATE);
Оптимизатор будет использовать этот индекс в запросах, подобных следующему, который возвращает номера служащих и их оклады для десяти последних служащих, которым были повышены оклады:
SELECT FIRST 10 EMP_NO, NEW_SALARY
FROM SALARY_HISTORY
ORDER BY CHANGE_DATE DESCENDING;
Если вы ожидаете использования как возрастающего, так и убывающего порядка сортировки по определенному столбцу, определите возрастающий и убывающий индексы для этого столбца. Например, будет замечательным создание следующего индекса в дополнение к индексу предыдущего примера:
CREATE ASCENDING INDEX ASCEND_X ON SALARY_HISTORY (CHANGE_DATE) ;
Индексы для нескольких столбцов
Если вашим приложениям часто требуется поиск, упорядочение или группировка по некоторой группе из нескольких столбцов в конкретной таблице, будет полезно создать индекс для нескольких столбцов (также называемый составным или композитным индексом).
Оптимизатор будет использовать подмножество сегментов такого индекса для оптимизации запроса, если порядок слева направо, в котором запрос обращается к столбцам в предложении ORDER BY, соответствует порядку слева направо в списке столбцов, определенному в индексе. При этом для запросов не требуется иметь в точности такой же список столбцов, как определено в индексе, чтобы индекс мог быть использован оптимизатором. Индекс также может быть использован, если подмножество
столбцов в предложении ORDER BY начинается с первого столбца индекса, определенного для нескольких столбцов.
Firebird может использовать один элемент составного индекса для оптимизации поиска, если все предшествующие элементы индекса также используются. Рассмотрим сегментированный индекс для трех столбцов col_w, col_x и col_y в том порядке, как показано на рис. 18.1.
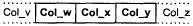
Рис. 18.1. Сегментированный индекс
Этот индекс будет использован оптимизатором для следующего запроса:
SELECT <���список столбцов> FROM ATABLE
ORDER BY COL_w, COL_X;
Он не будет использован для следующих запросов:
SELECT <���список столбцов> FROM ATABLE
ORDER BY COL_x, COL_y;
/**/
SELECT < список столбцов> FROM ATABLE
ORDER BY COL_x, COL_w;
Предикаты OR в запросах
Если вы ожидаете для таблицы частого выполнения запросов, которые используют оператор OR, то лучше создать индексы из одного столбца для каждого условия. Поскольку индексы из нескольких столбцов упорядочены иерархически, запрос, который использует одно из двух или более условий, должен просматривать всю таблицу, теряя преимущества использования индексов.
Предположим, требуется поиск:
. . .
WHERE А > 10000 OR В < 300 OR С BETWEEN 40 AND 80
. . .
Индекс для (А, В, С) будет использован для поиска строк, содержащих подходящие значения А, но он не может быть использован для поиска значений в или с. Для А убывающий индекс будет более полезным, чем возрастающий, если отыскиваемое значение находится в верхней части диапазона хранимых значений.
Критерии поиска
Те же самые правила, которые применяются к предложению ORDER BY, также применимы к запросам, содержащим предложение WHERE. Следующий пример создает индекс по нескольким столбцам для таблицы PROJECT В базе данных employee.gdb:
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Firebird РУКОВОДСТВО РАЗРАБОТЧИКА БАЗ ДАННЫХ»
Представляем Вашему вниманию похожие книги на «Firebird РУКОВОДСТВО РАЗРАБОТЧИКА БАЗ ДАННЫХ» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Firebird РУКОВОДСТВО РАЗРАБОТЧИКА БАЗ ДАННЫХ» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.