Любовь Лашкевич - Записки маркетолога. Чертеж вашего бизнеса
Здесь есть возможность читать онлайн «Любовь Лашкевич - Записки маркетолога. Чертеж вашего бизнеса» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. ISBN: , Издательство: Литагент Ридеро, Жанр: popular_business, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Записки маркетолога. Чертеж вашего бизнеса
- Автор:
- Издательство:Литагент Ридеро
- Жанр:
- Год:неизвестен
- ISBN:9785448384028
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Записки маркетолога. Чертеж вашего бизнеса: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Записки маркетолога. Чертеж вашего бизнеса»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Записки маркетолога. Чертеж вашего бизнеса — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Записки маркетолога. Чертеж вашего бизнеса», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
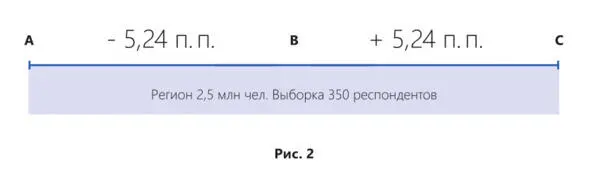
Например, мы вычислили, что доля использования антифриза владельцами автомобилей старше 1997 г. в. составляет 10,6% – это результат. Значит истина находится в диапазоне от 5,36% до 15,84%. Вычисление диапазона при получении результата в процентах:
Нижнее значение диапазона: 10,6% – 5,24 п. п. = 5,36%
Верхнее значение диапазона: 10,6% +5,24 п. п. = 15,84%
При расчетах в натуральном выражении, например, результат равен 100 автовладельцам, истина находится в диапазоне от 95 до 105 автовладельцев. Расчет:
Нижнее значение диапазона:
100 автовладельцев – 5,24% = 95 автовладельцев.
Верхнее значение диапазона:
100 автовладельцев +5,24% = 105 автовладельцев.
Большое это расхождение или маленькое? Возможно ли при таком отклонении делать объективные выводы для эффективной работы бизнеса?
В целом, ошибка допустимая. И с полученными данными можно работать. Но! Дальше – интереснее. Сотрудники маркетингового отдела компании Z принимают следующее решение. Так как исследование по региону происходило в определенных населенных пунктах, то почему бы не провести аналитику полученных данных по каждому населенному пункту?
Такое решение принимают без учета того, что ошибку выборки необходимо пересчитывать заново, уже под конкретный населенный пункт.
Например, в городе с населением 250 тыс. человек было опрошено 20 респондентов. Ошибка выборки в данном случае составит уже ± 21,91% (рис. 3).
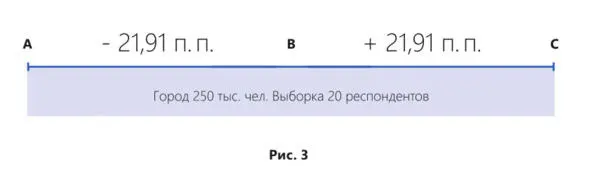
Что мы получаем в итоге. У нас есть результат исследований: доля потребления антифриза владельцев автомобилей старше 1997 г. в. составляет 10,6%. Вычисляем крайние значения, в которых может находиться истина:
Нижнее значение диапазона:
10,6% – 21,91 п. п. = отрицательное число.
Верхнее значение диапазона:
10,6% +21,91 п. п. = 32,51%
Значит истина находится в диапазоне от 0% до 32,51%.
При такой ошибке не стоит опираться на полученные цифры. Невооруженным взглядом видно, что при такой ошибке использование данных для принятия важных управленческих решений может привести к колоссальной ошибке в бизнесе.
Лучше в этой ситуации принять решение интуитивно. Риски будут те же, зато можно сэкономить деньги и потратить их на что-то более нужное – например, на канцелярию.
Глава 2. Сбор данных своими силами
Опасные средние
Достаточно часто в маркетинге используют понятие «средних», – в среднем по рынку в среднем «X» пользователей предпочитают «Y» товаров, и так далее. Понятие «средних» прочно вошло в жизнь бизнеса, на них строятся маркетинг-планы. На средние показатели ориентируются бизнес-стратегии. И мы настолько привыкли к этим средним, что порой не видим опасности, которую они скрывают.
Рассмотрим пример. В среднем по сети показатель уровня клиентского обслуживания составляет 85%. Хорошая цифра. Можно с гордостью эту цифру демонстрировать и спокойно жить до следующего исследования, аналитика которого построена на средних. Только почему-то, несмотря на высокую оценку клиентского обслуживания, проблемы не решаются, и клиенты недовольны. И самое главное – в процессе работы компании возникают вопросы, на которые нет ответов. Исследование, которое выдало столь высокую оценку, в итоге не дает инструмента для ответов на вопросы. Что произошло? А произошло то, что средние величины бывают коварны и таят в себе множество подводных камней. Ориентироваться на средние показатели стоит лишь в том случае, если вы работаете с узкими, четко описанными сегментами.
Давайте посмотрим, как средние величины могут обмануть исследователя, привести его к ошибочным выводам и неправильным управленческим решениям.
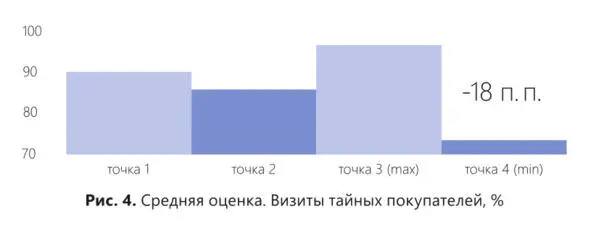
На рис. 4 мы видим, что были проведены исследования уровня клиентского обслуживания на четырех торговых точках. Результаты были рассчитаны с помощью средних величин. Торговая точка 4 показала самые низкие результаты. А остальные три торговые точки показали примерно одинаковые высокие результаты. Итогом такого исследования стало решение руководства премировать торговые точки 1, 2 и 3. А торговой точке 4 объявить взыскание за самый низкий показатель клиентского обслуживания.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Записки маркетолога. Чертеж вашего бизнеса»
Представляем Вашему вниманию похожие книги на «Записки маркетолога. Чертеж вашего бизнеса» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Записки маркетолога. Чертеж вашего бизнеса» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.